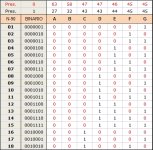
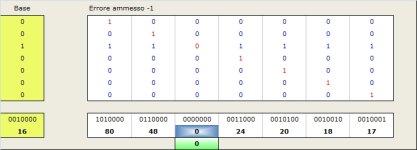
import os
import time
from datetime import datetime
from tkinter import Tk, filedialog, Checkbutton, IntVar, Button, Label, Entry, Frame
from collections import Counter, defaultdict
import winsound
class Logger:
def __init__(self, cartella_output):
self.start_time = time.time()
self.log_filename = os.path.join(cartella_output,
f"log_elaborazione_{datetime.now().strftime('%Y%m%d_%H%M%S')}.txt")
def log(self, messaggio):
with open(self.log_filename, 'a', encoding='utf-8') as f:
timestamp = datetime.now().strftime('%H:%M:%S')
f.write(f"[{timestamp}] {messaggio}\n")
print(messaggio)
def tempo_totale(self):
tempo_totale = time.time() - self.start_time
return f"{tempo_totale:.2f} secondi"
class ReportCasiOttimali:
def __init__(self, cartella_output):
self.report_path = os.path.join(cartella_output, "reportcasiottimali.txt")
with open(self.report_path, 'w', encoding='utf-8') as f:
f.write("=== Report Casi Ottimali ===\n\n")
self.casi_trovati = False
def aggiungi_caso(self, file_estrazioni, file_b, posizione, prob_0, prob_1):
self.casi_trovati = True
with open(self.report_path, 'a', encoding='utf-8') as f:
f.write(f"File estrazioni: {file_estrazioni}\n")
f.write(f"File binario: {file_b}\n")
f.write(f"Probabilità '0': {prob_0:.2%}\n")
f.write(f"Probabilità '1': {prob_1:.2%}\n")
f.write("-" * 50 + "\n")
def finalizza_report(self):
if not self.casi_trovati:
with open(self.report_path, 'a', encoding='utf-8') as f:
f.write("Nessun caso ottimale trovato.\n")
class ReportRuote:
def __init__(self, cartella_output, nome_file):
self.report_path = os.path.join(cartella_output, nome_file)
if not os.path.exists(self.report_path):
with open(self.report_path, 'w', encoding='utf-8') as f:
f.write(f"=== {nome_file.replace('.txt', '').upper()} ===\n\n")
def aggiungi_ruota(self, ruota):
with open(self.report_path, 'a', encoding='utf-8') as f:
f.write(f"{ruota}\n")
class CarrelloPredizioni:
def __init__(self):
self.carrelli = defaultdict(lambda: ['_'] * 7)
self.ruota_corrente = None
def set_ruota(self, nome_file_input):
if nome_file_input.startswith('estrazioni-'):
self.ruota_corrente = nome_file_input.split('-')[1].split('.')[0]
def aggiungi_predizione(self, file_origine, posizione, valore):
file_base = os.path.basename(file_origine)
parti = file_base.split('-')
numero_file = ''.join(filter(str.isdigit, parti[0]))
chiave = f"b{numero_file}"
try:
posizione = int(parti[1].split('.')[0])
if 0 <= posizione < 7:
self.carrelli[chiave][posizione] = valore
except (ValueError, IndexError) as e:
print(f"Errore: {e}")
def mostra_risultati(self, logger, cartella_output):
logger.log("\n=== Risultati Finali ===")
script_dir = os.path.dirname(os.path.abspath(__file__))
report_path = os.path.join(script_dir, "previsionielaborate.txt")
numeri_decimali = []
for chiave in sorted(self.carrelli.keys()):
sequenza_binaria = ''.join(self.carrelli[chiave])
numero_decimale = str(int(sequenza_binaria, 2))
numeri_decimali.append(numero_decimale)
logger.log(f"{chiave}.txt: {numero_decimale} (binario: {sequenza_binaria} = {int(sequenza_binaria, 2)})")
with open(report_path, 'a', encoding='utf-8') as report:
if self.ruota_corrente and numeri_decimali:
report.write(f"{self.ruota_corrente} {'-'.join(numeri_decimali)}\n")
logger.log("=====================")
logger.log(f"Report salvato in: {report_path}")
def decimale_a_binario(decimale):
return '.'.join(format(int(decimale), '07b'))
def converte_file_decimale(file_decimale, cartella_output, logger):
colonne = []
with open(file_decimale, 'r') as file:
for linea in file:
valori = linea.strip().split('.')
for i, valore in enumerate(valori):
if len(colonne) <= i:
colonne.append([])
colonne[i].append(decimale_a_binario(valore))
file_binari = []
for i, colonna in enumerate(colonne):
nome_file = os.path.join(cartella_output, f"b{i + 1}.txt")
with open(nome_file, 'w') as file:
file.write('\n'.join(colonna))
file_binari.append(nome_file)
logger.log(f"File binario generato: {nome_file}")
return file_binari
def split_file_binario(file_binario, cartella_output, logger):
base_name = os.path.basename(file_binario)
numero_file = ''.join(filter(str.isdigit, base_name.split('.')[0]))
with open(file_binario, 'r') as file:
righe = [line.strip().split('.') for line in file]
colonne = list(zip(*righe))
file_splittati = []
for i, colonna in enumerate(colonne):
nome_file = os.path.join(cartella_output, f"b{numero_file}-{i}.txt")
with open(nome_file, 'w') as file:
file.write('\n'.join(colonna))
file_splittati.append(nome_file)
logger.log(f"File splittato generato: {nome_file}")
return file_splittati
def carica_dati(file_path):
with open(file_path, 'r') as file:
# Legge i dati e INVERTE l'ordine per avere i più vecchi in alto durante l'analisi
dati = [bit for line in file for bit in line.strip().split('.')]
return dati[::-1] # <-- Modifica chiave qui
def analizza_file(file_binario, lunghezza_sequenza, carrello, logger, report_ottimali, file_estrazioni,
soglia_minima, analisi_automatica):
posizione = int(os.path.basename(file_binario).split('-')[1].split('.')[0])
dati = carica_dati(file_binario) # Dati ora sono invertiti: [vecchio, ..., recente]
logger.log(f"\nAnalisi pattern per {file_binario}")
logger.log(f"Posizione bit analizzata: bit{posizione}.txt")
logger.log(f"Lunghezza sequenza pattern: {lunghezza_sequenza}")
# Controllo per assicurarsi che la lunghezza del pattern sia valida
if lunghezza_sequenza <= 0:
logger.log(f"Lunghezza sequenza pattern non valida: {lunghezza_sequenza}")
return False
# Pattern iniziale preso dalla FINE dei dati invertiti (corrisponde ai più RECENTI nel file originale)
initial_pattern = tuple(dati[-lunghezza_sequenza:]) # <-- Modifica qui
preceding_bits = []
# Analizza dal basso (vecchio) verso l'alto (recente) nei dati invertiti
for i in range(len(dati) - lunghezza_sequenza):
current_window = tuple(dati[i:i + lunghezza_sequenza])
if current_window == initial_pattern and i + lunghezza_sequenza < len(dati):
# Il bit successivo è quello DOPO la finestra, verso l'alto (più recente)
preceding_bit = dati[i + lunghezza_sequenza]
preceding_bits.append(preceding_bit)
count_0 = preceding_bits.count('0')
count_1 = preceding_bits.count('1')
total = len(preceding_bits)
if total == 0:
prob_0, prob_1 = 0.5, 0.5
else:
prob_0 = count_0 / total
prob_1 = count_1 / total
occ = {'0': count_0, '1': count_1}
TOLLERANZA = 0.0001
is_optimal = any(abs(prob - 1.0) < TOLLERANZA for prob in [prob_0, prob_1])
# Controllo per identificare i casi con esattamente un bit inferiore alla soglia minima
if analisi_automatica:
bit_inferiori = [bit for bit in preceding_bits if (bit == '0' and prob_0 < soglia_minima / 100) or (bit == '1' and prob_1 < soglia_minima / 100)]
if len(bit_inferiori) == 1:
file_b = os.path.basename(file_binario).split('-')[0] + ".txt"
report_ottimali.aggiungi_caso(
os.path.basename(file_estrazioni),
file_b,
posizione,
prob_0,
prob_1
)
return True
valore_predetto = '0' if prob_0 > prob_1 else '1'
prob_valore = prob_0 if valore_predetto == '0' else prob_1
logger.log(f"Sequenza iniziale: {''.join(initial_pattern)}")
logger.log(f"Occorrenze trovate del pattern: {total}")
logger.log(f"Probabilità '0': {prob_0:.2%} (occorrenze: {count_0})")
logger.log(f"Probabilità '1': {prob_1:.2%} (occorrenze: {count_1})")
logger.log(f"Valore predetto: {valore_predetto} (probabilità: {prob_valore:.2%})")
carrello.aggiungi_predizione(file_binario, posizione, valore_predetto)
# Aggiunto controllo per fermarsi se tutte le probabilità sono maggiori o uguali alla soglia
if prob_0 >= soglia_minima / 100 and prob_1 >= soglia_minima / 100:
return True
return is_optimal
def processo_automatico(file_input, lunghezza_sequenza, righe_da_analizzare=10000, soglia_minima=100, analisi_automatica=False):
cartella_output = os.path.dirname(os.path.abspath(file_input))
nome_file = os.path.basename(file_input)
logger = Logger(cartella_output)
report_ottimali = ReportCasiOttimali(cartella_output)
report_ruote_ottimali = ReportRuote(os.path.dirname(os.path.abspath(__file__)), "RUOTEOTTIMALI.txt")
report_ruote_non_ottimali = ReportRuote(os.path.dirname(os.path.abspath(__file__)), "RUOTENONOTTIMALI.txt")
logger.log(f"Inizio elaborazione")
logger.log(f"File input: {nome_file}")
logger.log(f"Cartella output: {cartella_output}")
logger.log(f"Lunghezza sequenza: {lunghezza_sequenza}")
logger.log(f"Righe da analizzare: {righe_da_analizzare}")
logger.log(f"Soglia minima: {soglia_minima}%")
logger.log("\nConversione file decimale in binari...")
with open(file_input, 'r') as file:
lines = []
for i, line in enumerate(file):
if i < righe_da_analizzare:
lines.append(line)
else:
break
temp_file = os.path.join(cartella_output, "temp_estrazioni.txt")
with open(temp_file, 'w') as file:
file.writelines(lines)
file_binari = converte_file_decimale(temp_file, cartella_output, logger)
carrello = CarrelloPredizioni()
carrello.set_ruota(nome_file)
is_ruota_ottimale = True
for file_binario in file_binari:
logger.log(f"\nElaborazione {os.path.basename(file_binario)}...")
file_splittati = split_file_binario(file_binario, cartella_output, logger)
for file_splittato in file_splittati:
if not analizza_file(file_splittato, lunghezza_sequenza, carrello, logger, report_ottimali, nome_file, soglia_minima, analisi_automatica):
is_ruota_ottimale = False
if is_ruota_ottimale:
report_ruote_ottimali.aggiungi_ruota(carrello.ruota_corrente)
else:
report_ruote_non_ottimali.aggiungi_ruota(carrello.ruota_corrente)
carrello.mostra_risultati(logger, cartella_output)
report_ottimali.finalizza_report()
tempo_totale = logger.tempo_totale()
logger.log(f"\nTempo totale di elaborazione: {tempo_totale}")
logger.log(f"Report casi ottimali salvato in: {report_ottimali.report_path}")
logger.log(f"Report ruote ottimali salvato in: {report_ruote_ottimali.report_path}")
logger.log(f"Report ruote non ottimali salvato in: {report_ruote_non_ottimali.report_path}")
os.remove(temp_file)
return report_ottimali.casi_trovati
def ottieni_percorso_file_estrazioni(ruota):
return os.path.join(ruota, f"estrazioni-{ruota}.txt")
def inizializza_report_ruote():
script_dir = os.path.dirname(os.path.abspath(__file__))
for nome_file in ["RUOTEOTTIMALI.txt", "RUOTENONOTTIMALI.txt"]:
report_path = os.path.join(script_dir, nome_file)
with open(report_path, 'w', encoding='utf-8') as f:
f.write(f"=== {nome_file.replace('.txt', '').upper()} ===\n\n")
def main():
root = Tk()
root.title("Seleziona Ruote")
pattern_frame = Frame(root)
pattern_frame.pack(pady=10)
Label(pattern_frame, text="Lunghezza pattern:").pack(side='left')
pattern_length = Entry(pattern_frame, width=5)
pattern_length.insert(0, "18")
pattern_length.pack(side='left', padx=5)
righe_frame = Frame(root)
righe_frame.pack(pady=10)
Label(righe_frame, text="Prime righe da analizzare:").pack(side='left')
righe_da_analizzare = Entry(righe_frame, width=5)
righe_da_analizzare.insert(0, "10000")
righe_da_analizzare.pack(side='left', padx=5)
soglia_frame = Frame(root)
soglia_frame.pack(pady=10)
Label(soglia_frame, text="Soglia minima di probabilità (%):").pack(side='left')
soglia_minima = Entry(soglia_frame, width=5)
soglia_minima.insert(0, "100")
soglia_minima.pack(side='left', padx=5)
analisi_automatica_var = IntVar()
Checkbutton(root, text="Analisi e selezione automatica", variable=analisi_automatica_var).pack(pady=5)
Label(root, text="Seleziona le ruote da analizzare:").pack()
ruote = ["BA", "CA", "FI", "GE", "MI", "NA", "PA", "RO", "TO", "VE", "NZ"]
ruote_vars = {ruota: IntVar() for ruota in ruote}
checkbuttons_frame = Frame(root)
checkbuttons_frame.pack(pady=5)
for ruota in ruote:
Checkbutton(checkbuttons_frame, text=ruota, variable=ruote_vars[ruota]).pack(anchor='w')
buttons_frame = Frame(root)
buttons_frame.pack(pady=10)
def seleziona_tutto():
for var in ruote_vars.values():
var.set(1)
def deseleziona_tutto():
for var in ruote_vars.values():
var.set(0)
def analizza():
try:
lunghezza_seq = int(pattern_length.get())
righe = int(righe_da_analizzare.get())
soglia = float(soglia_minima.get())
analisi_automatica = analisi_automatica_var.get()
ruote_selezionate = [ruota for ruota, var in ruote_vars.items() if var.get()]
inizializza_report_ruote()
if analisi_automatica:
lunghezza_seq_iniziale = lunghezza_seq
while True:
casi_trovati = False
for ruota in ruote_selezionate:
file_input = ottieni_percorso_file_estrazioni(ruota)
if os.path.exists(file_input):
logger = Logger(os.path.dirname(os.path.abspath(file_input)))
logger.log(f"Analizzando ruota: {ruota}")
logger.log(f"File input: {file_input}")
logger.log(f"Lunghezza sequenza: {lunghezza_seq}")
logger.log(f"Righe da analizzare: {righe}")
logger.log(f"Soglia minima: {soglia}%")
if processo_automatico(file_input, lunghezza_seq, righe, soglia, analisi_automatica):
casi_trovati = True
logger.log(f"Ruota ottimale trovata: {ruota}")
report_ruote_ottimali = ReportRuote(os.path.dirname(os.path.abspath(__file__)), "RUOTEOTTIMALI.txt")
report_ruote_ottimali.aggiungi_ruota(f"RUOTA OTTIMALE: {ruota}")
winsound.Beep(1000, 2000) # Emette un bip sonoro a 1000 Hz per 2 secondi
break
if casi_trovati:
break
lunghezza_seq += 1
logger.log(f"Aumentando la lunghezza del pattern a {lunghezza_seq}")
else:
for ruota in ruote_selezionate:
file_input = ottieni_percorso_file_estrazioni(ruota)
if os.path.exists(file_input):
logger = Logger(os.path.dirname(os.path.abspath(file_input)))
logger.log(f"Analizzando ruota: {ruota}")
logger.log(f"File input: {file_input}")
logger.log(f"Lunghezza sequenza: {lunghezza_seq}")
logger.log(f"Righe da analizzare: {righe}")
logger.log(f"Soglia minima: {soglia}%")
processo_automatico(file_input, lunghezza_seq, righe, soglia, analisi_automatica)
else:
print(f"File di estrazioni per la ruota {ruota} non trovato.")
except ValueError:
print("Errore: inserire valori numerici validi.")
Button(buttons_frame, text="Seleziona Tutto", command=seleziona_tutto).pack(side='left', padx=5)
Button(buttons_frame, text="Deseleziona Tutto", command=deseleziona_tutto).pack(side='left', padx=5)
Button(buttons_frame, text="Analizza", command=analizza).pack(side='left', padx=5)
root.mainloop()
if __name__ == "__main__":
main()




") ho semplicemente aperto il log.txt relativo a quella elaborazione con notepad++
ho semplicemente aperto il log.txt relativo a quella elaborazione con notepad++ 
 . In sostanza la squadra AI si incrementa di un forte player: Claude+ChatGPT+DeepSeek+Mistral+Gemini+GoogleNotebookLM+Cursor.
. In sostanza la squadra AI si incrementa di un forte player: Claude+ChatGPT+DeepSeek+Mistral+Gemini+GoogleNotebookLM+Cursor.