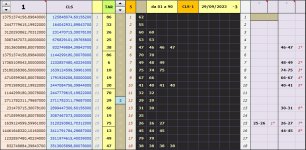
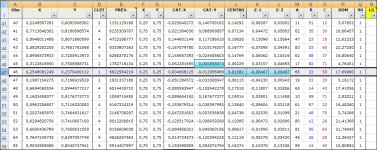
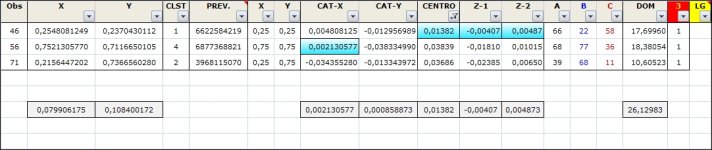
Ciao halmun ogni tanto anche io riprendo l'argomento, per me totalmente nuovo, di rete neurale, sopratutto grazie a chatgpt che mi insegna a piccoli passi alcuni aspetti relativi... Ad ogni modo... empiricamente ho provato ad analizzare le attuali 10311 estrazioni su BARI con un mio ultimo script in python sempre realizzato grazie a lei basandosi su un suo precedente script che aveva creato in R e mi avrebbe trovato in un nanosecondo questi parametri per un cluster di 5 elementi per i quali non so se l'analisi si riferisca a singolo estratto o a sorte maggiore:
TotalError: 44.64888102838848
AverageError: 44.64888102838848
Ti chiedo se possono essere plausibili o se, secondo te, è andata totalmente di fuori rispetto le tue approfondite conoscenze al riguardo.
La cosa curiosa è che anche su RO (la prima ruota testata similarmente) avrebbe valori simili...

Grazie per un tuo spassionato parere.







")







