Halmun
Advanced Member >PLATINUM<
chiariamo una volta per tutte un aspetto che 20 anni fa in questo forum fu messo in discussione da chi sosteneva Erroneamente che le Reti neurali SOM come NNCLUST o altre Reti di diverso tipo non utilizzano operatori matematici:
Tratto da domande e risposte con A.I. Gemini.
io:
.... capisco, ma un algoritmo di apprendimento utilizza comunque operatori matematici per giungere all'apprendimento. giusto?
Gemini:
Assolutamente sì! Un algoritmo di apprendimento, e in particolare quello di una rete neurale, si basa su una serie complessa di operazioni matematiche. Queste operazioni permettono alla rete di "imparare" dai dati, identificando pattern e relazioni nascoste.
Quali sono questi operatori matematici?
Somme pesate: Ogni neurone all'interno della rete riceve numerosi input, ciascuno moltiplicato per un peso specifico. Questi prodotti vengono poi sommati. I pesi sono i parametri che la rete "apprende" durante l'addestramento e determinano l'importanza relativa di ciascun input.
Funzioni di attivazione: Dopo la somma pesata, il risultato viene passato attraverso una funzione di attivazione non lineare (come la sigmoidale, la ReLU o la tanh). Queste funzioni introducono non linearità nella rete, permettendole di approssimare funzioni più complesse.
Calcolo dell'errore: L'errore viene calcolato come la differenza tra l'output previsto dalla rete e l'output reale. Questo errore viene poi utilizzato per aggiornare i pesi.
Discesa del gradiente: Questo è l'algoritmo più comunemente utilizzato per l'addestramento delle reti neurali. Calcola il gradiente della funzione di costo rispetto ai pesi e aggiorna i pesi in direzione opposta al gradiente, in modo da ridurre l'errore.
Moltiplicazione di matrici: Le reti neurali possono essere rappresentate come una serie di matrici, e le operazioni di propagazione in avanti e all'indietro coinvolgono moltiplicazioni di matrici.
Perché le operazioni matematiche sono fondamentali?
Rappresentazione: Le operazioni matematiche permettono di rappresentare in modo compatto e efficiente le relazioni tra i dati.
Apprendimento: Attraverso l'aggiornamento dei pesi, la rete può modificare la sua rappresentazione interna dei dati e adattarsi a nuovi esempi.
Generalizzazione: Le operazioni matematiche consentono alla rete di generalizzare a nuovi dati, ovvero di fare previsioni accurate su dati che non ha mai visto durante l'addestramento.
In sintesi
Le reti neurali utilizzano un linguaggio matematico sofisticato per apprendere dai dati. Le operazioni matematiche sono il fondamento su cui si basa il loro funzionamento. Comprendere queste operazioni è fondamentale per poter sfruttare al meglio le potenzialità delle reti neurali.
io:
e questo vale anche per le reti SOM?
Gemini:
Assolutamente sì, anche le reti SOM (Self-Organizing Maps) si basano su operazioni matematiche.
Sebbene le SOM presentino alcune differenze rispetto alle reti neurali artificiali tradizionali, come le MLP (Multi-Layer Perceptron), condividono con esse il fondamento matematico.
Come funzionano le operazioni matematiche nelle SOM?
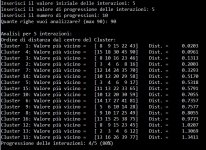
Competizione tra neuroni: Ogni neurone della SOM compete per rispondere a un dato input. Il neurone vincente è quello i cui pesi sono più simili all'input.
Aggiornamento dei pesi: I pesi del neurone vincente e dei suoi vicini vengono aggiornati in modo da diventare più simili all'input. Questa operazione è basata su una funzione di vicinato e su un tasso di apprendimento.
Mappa topologica: La struttura della SOM è organizzata in una griglia bidimensionale. La vicinanza spaziale dei neuroni nella mappa riflette la similarità degli input che essi rappresentano.
Quali operazioni matematiche sono coinvolte?
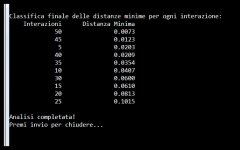
Distanza euclidea: Viene utilizzata per calcolare la somiglianza tra l'input e i pesi di ciascun neurone.
Funzione di vicinato: Definisce l'ampiezza del vicinato del neurone vincente i cui pesi verranno aggiornati.
Tasso di apprendimento: Determina la velocità con cui i pesi vengono aggiornati.
Aggiornamento dei pesi: Questa operazione è solitamente implementata utilizzando una formula di aggiornamento simile a quella utilizzata nelle reti neurali tradizionali, ma adattata alla struttura della SOM.
In sintesi
Anche se le SOM hanno un approccio diverso all'apprendimento rispetto alle MLP, esse si basano su principi matematici ben definiti. La competizione tra neuroni, l'aggiornamento dei pesi e la formazione di una mappa topologica sono tutte operazioni che coinvolgono calcoli matematici.
Perché è importante conoscere le basi matematiche delle SOM?
Comprendere il funzionamento:
Conoscere le operazioni matematiche sottostanti ti permette di capire come la SOM apprende e organizza i dati.
Scegliere i parametri:
La scelta dei parametri (tasso di apprendimento, funzione di vicinato, ecc.) influisce significativamente sulle prestazioni della SOM.
Risolvere problemi:
Se incontri problemi durante l'utilizzo di una SOM, la conoscenza delle basi matematiche ti aiuterà a identificarne le cause e a trovare soluzioni.
Adattare la SOM:
Potresti voler adattare la SOM a un problema specifico. Conoscere le basi matematiche ti permetterà di modificare l'algoritmo in modo appropriato.
Tratto da domande e risposte con A.I. Gemini.
io:
.... capisco, ma un algoritmo di apprendimento utilizza comunque operatori matematici per giungere all'apprendimento. giusto?
Gemini:
Assolutamente sì! Un algoritmo di apprendimento, e in particolare quello di una rete neurale, si basa su una serie complessa di operazioni matematiche. Queste operazioni permettono alla rete di "imparare" dai dati, identificando pattern e relazioni nascoste.
Quali sono questi operatori matematici?
Somme pesate: Ogni neurone all'interno della rete riceve numerosi input, ciascuno moltiplicato per un peso specifico. Questi prodotti vengono poi sommati. I pesi sono i parametri che la rete "apprende" durante l'addestramento e determinano l'importanza relativa di ciascun input.
Funzioni di attivazione: Dopo la somma pesata, il risultato viene passato attraverso una funzione di attivazione non lineare (come la sigmoidale, la ReLU o la tanh). Queste funzioni introducono non linearità nella rete, permettendole di approssimare funzioni più complesse.
Calcolo dell'errore: L'errore viene calcolato come la differenza tra l'output previsto dalla rete e l'output reale. Questo errore viene poi utilizzato per aggiornare i pesi.
Discesa del gradiente: Questo è l'algoritmo più comunemente utilizzato per l'addestramento delle reti neurali. Calcola il gradiente della funzione di costo rispetto ai pesi e aggiorna i pesi in direzione opposta al gradiente, in modo da ridurre l'errore.
Moltiplicazione di matrici: Le reti neurali possono essere rappresentate come una serie di matrici, e le operazioni di propagazione in avanti e all'indietro coinvolgono moltiplicazioni di matrici.
Perché le operazioni matematiche sono fondamentali?
Rappresentazione: Le operazioni matematiche permettono di rappresentare in modo compatto e efficiente le relazioni tra i dati.
Apprendimento: Attraverso l'aggiornamento dei pesi, la rete può modificare la sua rappresentazione interna dei dati e adattarsi a nuovi esempi.
Generalizzazione: Le operazioni matematiche consentono alla rete di generalizzare a nuovi dati, ovvero di fare previsioni accurate su dati che non ha mai visto durante l'addestramento.
In sintesi
Le reti neurali utilizzano un linguaggio matematico sofisticato per apprendere dai dati. Le operazioni matematiche sono il fondamento su cui si basa il loro funzionamento. Comprendere queste operazioni è fondamentale per poter sfruttare al meglio le potenzialità delle reti neurali.
io:
e questo vale anche per le reti SOM?
Gemini:
Assolutamente sì, anche le reti SOM (Self-Organizing Maps) si basano su operazioni matematiche.
Sebbene le SOM presentino alcune differenze rispetto alle reti neurali artificiali tradizionali, come le MLP (Multi-Layer Perceptron), condividono con esse il fondamento matematico.
Come funzionano le operazioni matematiche nelle SOM?
Competizione tra neuroni: Ogni neurone della SOM compete per rispondere a un dato input. Il neurone vincente è quello i cui pesi sono più simili all'input.
Aggiornamento dei pesi: I pesi del neurone vincente e dei suoi vicini vengono aggiornati in modo da diventare più simili all'input. Questa operazione è basata su una funzione di vicinato e su un tasso di apprendimento.
Mappa topologica: La struttura della SOM è organizzata in una griglia bidimensionale. La vicinanza spaziale dei neuroni nella mappa riflette la similarità degli input che essi rappresentano.
Quali operazioni matematiche sono coinvolte?
Distanza euclidea: Viene utilizzata per calcolare la somiglianza tra l'input e i pesi di ciascun neurone.
Funzione di vicinato: Definisce l'ampiezza del vicinato del neurone vincente i cui pesi verranno aggiornati.
Tasso di apprendimento: Determina la velocità con cui i pesi vengono aggiornati.
Aggiornamento dei pesi: Questa operazione è solitamente implementata utilizzando una formula di aggiornamento simile a quella utilizzata nelle reti neurali tradizionali, ma adattata alla struttura della SOM.
In sintesi
Anche se le SOM hanno un approccio diverso all'apprendimento rispetto alle MLP, esse si basano su principi matematici ben definiti. La competizione tra neuroni, l'aggiornamento dei pesi e la formazione di una mappa topologica sono tutte operazioni che coinvolgono calcoli matematici.
Perché è importante conoscere le basi matematiche delle SOM?
Comprendere il funzionamento:
Conoscere le operazioni matematiche sottostanti ti permette di capire come la SOM apprende e organizza i dati.
Scegliere i parametri:
La scelta dei parametri (tasso di apprendimento, funzione di vicinato, ecc.) influisce significativamente sulle prestazioni della SOM.
Risolvere problemi:
Se incontri problemi durante l'utilizzo di una SOM, la conoscenza delle basi matematiche ti aiuterà a identificarne le cause e a trovare soluzioni.
Adattare la SOM:
Potresti voler adattare la SOM a un problema specifico. Conoscere le basi matematiche ti permetterà di modificare l'algoritmo in modo appropriato.
Ultima modifica:
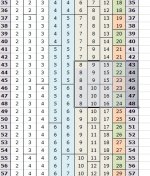
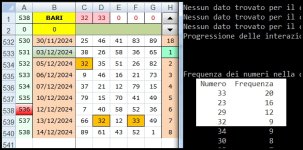
") Riguardo a questo esempio avresti beccato 66 al 1° colpo e 43 al 2° in classe 4 su ruota unica di BA vero?
Riguardo a questo esempio avresti beccato 66 al 1° colpo e 43 al 2° in classe 4 su ruota unica di BA vero?