How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Nota: This feature may not be available in some browsers.
Stai usando un browser molto obsoleto. Puoi incorrere in problemi di visualizzazione di questo e altri siti oltre che in problemi di sicurezza. .
Dovresti aggiornarlo oppure usare usarne uno alternativo, moderno e sicuro.
Dovresti aggiornarlo oppure usare usarne uno alternativo, moderno e sicuro.
Script biambo
- Creatore Discussione Cinzia27
- Data di inizio
Acquafresca
Super Member >PLATINUM<
Buonasera Cinzia27,non saprei darti suggerimenti a riguardo , sono dietro a capire di risolvere lo script e semplificarlo come se fosse un'Applicazione Unica da mettere sul desktop e avviarla ,senza tante complicazioni e che unisca le varie opzioni di analisi ,non è cosa semplice (ma sicuramente fattibile)Ciao, Acquafresca, Genios e quanti seguono il 3D
1.4;3.25;32.64 mx st 33 at 16
Ritenete che si possa superare?
Ciao, Acquafresca, ho provato a far girare il file precedente, direi un buon lavoro e sopratutto veloce rispetto alla velocità in spaziometria, ora hai postato questo giustamente adattato al tuo archivio ma non ho capito comè è realizzato, a prte csv parli di virgole su ogni estratto compreso le date, per capirne la logica e vedere cosa sviluppa.Altro script per Cinzia27 verificare gli Biambi Sfaldati:che se qualche partecipante del forum più esperto potrebbe agganciarli sarebbe molto utile un eseguibile tipo icona su desktop.
Codice
"""
BIAMBI CON RITARDO MASSIMO STORICO <= SOGLIA + RITARDO ATTUALE
===============================================================
Versione ottimizzata per CSV con report dei biambi sfaldati nell'ultima estrazione
- 11 ruote (inclusa la Nazionale)
- Ricerca parte dall'estrazione con ID = 8117
"""
import os
import sys
import time
import csv
import numpy as np
from itertools import combinations
# --- CONFIGURAZIONE PERCORSI AUTOMATICI ---
if getattr(sys, 'frozen', False):
cartella_exe = os.path.dirname(sys.executable)
else:
cartella_exe = os.path.dirname(os.path.abspath(__file__))
ARCHIVIO = os.path.join(cartella_exe, "estrazioni.csv")
OUTPUT = os.path.join(cartella_exe, "biambi_sotto79.txt")
OUTPUT_SFALDATI = os.path.join(cartella_exe, "biambi_sfaldati.txt")
SOGLIA = 100
ID_INIZIO = 8117 # prima estrazione da considerare (1-based)
NUM_RUOTE = 11 # tutte e 11 le ruote inclusa Nazionale
NUM_ESTRATTI = 5
NUM_AMBI = 4005
NUM_COPPIE = 8_018_010
COMBO_5_2 = list(combinations(range(NUM_ESTRATTI), 2))
NOMI_RUOTE = [
"Bari","Cagliari","Firenze","Genova","Milano",
"Napoli","Palermo","Roma","Torino","Venezia","Nazionale"
]
def ambo_idx(a, b):
if a > b: a, b = b, a
return (a - 1) * 90 - a * (a - 1) // 2 + (b - a - 1)
def idx_to_ambo(idx):
a = 1
while idx >= (90 - a):
idx -= (90 - a)
a += 1
return a, a + 1 + idx
def coppia_idx(i, j):
if i > j: i, j = j, i
return i * (NUM_AMBI - 1) - i * (i + 1) // 2 + j - 1
def idx_to_coppia(ci):
i = 0
while ci >= (NUM_AMBI - 1 - i):
ci -= (NUM_AMBI - 1 - i)
i += 1
return i, i + 1 + ci
def fmt(d):
return str(d)
def leggi_archivio(path):
estrazioni, date = [], []
with open(path, "r", encoding="utf-8") as f:
reader = csv.reader(f)
for lineno, row in enumerate(reader, 1):
if not row or len(row) < 2:
continue
# Controllo corretto dell'intestazione (senza usare lower sulla lista)
testo_prima_cella = str(row[0]).strip().lower()
if lineno == 1 or testo_prima_cella.startswith("data"):
continue
id_reale = lineno - 1
if id_reale < ID_INIZIO:
continue
# La data è il primo elemento della riga
data = row[0]
# Converte i numeri saltando celle vuote
valori_numerici = []
for x in row[1:]:
if x.strip() != "":
try:
valori_numerici.append(int(float(x)))
except ValueError:
valori_numerici.append(0)
ruote = []
for r in range(NUM_RUOTE):
off = r * NUM_ESTRATTI
nums = valori_numerici[off : off + NUM_ESTRATTI]
# Se mancano numeri per la ruota inserisce zeri di riempimento
while len(nums) < NUM_ESTRATTI:
nums.append(0)
ruote.append(nums)
date.append(data)
estrazioni.append(ruote)
return np.array(estrazioni, dtype=np.int16), date
def build_arrays():
print(" Precalcolo array coppie...", end=" ", flush=True)
t0 = time.time()
ambo_i_arr = np.empty(NUM_COPPIE, dtype=np.int32)
ambo_j_arr = np.empty(NUM_COPPIE, dtype=np.int32)
ci = 0
for i in range(NUM_AMBI):
n = NUM_AMBI - i - 1
ambo_i_arr[ci:ci+n] = i
ambo_j_arr[ci:ci+n] = np.arange(i+1, NUM_AMBI, dtype=np.int32)
ci += n
print(f"fatto in {time.time()-t0:.1f}s")
return ambo_i_arr, ambo_j_arr
def calcola(arr, ambo_i_arr, ambo_j_arr):
N = arr.shape[0]
print(f"\n Estrazioni usate : {N:,} (dal ID {ID_INIZIO} in poi)")
print(f" Ruote : {NUM_RUOTE} ({', '.join(NOMI_RUOTE)})")
print(f" Coppie : {NUM_COPPIE:,}")
print(f" Soglia : <= {SOGLIA}\n")
rit_cor = np.zeros(NUM_COPPIE, dtype=np.uint16)
rit_max = np.zeros(NUM_COPPIE, dtype=np.uint16)
t0 = time.time()
ultimi_ambi_usciti = set()
for idx_e in range(N):
if idx_e % 200 == 0:
el = time.time() - t0
pct = idx_e / N * 100
eta = (el / (idx_e + 1)) * (N - idx_e) if idx_e > 0 else 0
print(f" [{idx_e:6,}/{N:,}] {pct:.1f}% ETA: {eta:.0f}s ", end="\r")
ambi_usciti = set()
for r in range(NUM_RUOTE):
nums = arr[idx_e, r]
for c1, c2 in COMBO_5_2:
a, b = int(nums[c1]), int(nums[c2])
if a > 0 and b > 0:
ambi_usciti.add(ambo_idx(a, b))
if idx_e == N - 1:
ultimi_ambi_usciti = ambi_usciti.copy()
if not ambi_usciti:
rit_cor += 1
continue
ambi_arr = np.fromiter(ambi_usciti, dtype=np.int32)
mask = np.isin(ambo_i_arr, ambi_arr) | np.isin(ambo_j_arr, ambi_arr)
rit_max[mask] = np.maximum(rit_max[mask], rit_cor[mask])
rit_cor[mask] = 0
rit_cor += 1
np.maximum(rit_max, rit_cor, out=rit_max)
print(f"\n Completato in {time.time()-t0:.1f}s")
return rit_max, rit_cor, ultimi_ambi_usciti
def salva(rit_max, rit_att, date, ultimi_ambi_usciti):
print(f"\n Filtro coppie con rit_max <= {SOGLIA}...")
idx_ok = np.where(rit_max <= SOGLIA)[0]
ord_key = np.lexsort((-rit_att[idx_ok], rit_max[idx_ok]))
idx_ok = idx_ok[ord_key]
totale = len(idx_ok)
print(f" Coppie trovate: {totale:,}")
print("\n" + "="*58)
print(f" BIAMBI CON RITARDO MASSIMO STORICO <= {SOGLIA}")
print(f" Dal ID {ID_INIZIO}: {fmt(date[0])} → {fmt(date[-1])}")
print(f" Ruote: tutte e 11 (inclusa Nazionale)")
print(f" Trovate: {totale:,}")
print("="*58)
print(f" {'Pos':>8} {'Ambo 1':>7} {'Ambo 2':>7} {'Rit.Max':>8} {'Rit.Att':>8}")
print(" " + "-"*52)
righe = []
righe_sfaldate = []
for rank, ci in enumerate(idx_ok, 1):
ai, aj = idx_to_coppia(int(ci))
a1, b1 = idx_to_ambo(ai)
a2, b2 = idx_to_ambo(aj)
mx = int(rit_max[ci])
att = int(rit_att[ci])
si_e_sfaldato = (ai in ultimi_ambi_usciti) or (aj in ultimi_ambi_usciti)
riga = f"{rank:>8}. {a1:02d}-{b1:02d} {a2:02d}-{b2:02d} {mx:>8} {att:>8}"
righe.append(riga)
if si_e_sfaldato:
righe_sfaldate.append(riga)
if rank <= 50:
print(" " + riga)
if totale > 50:
print(f"\n ... totale {totale:,} coppie — tutte nel file")
print("="*58)
header = (
f"BIAMBI CON RITARDO MASSIMO STORICO <= {SOGLIA}\n"
f"Archivio : {fmt(date[0])} -> {fmt(date[-1])}\n"
f"ID inizio : {ID_INIZIO}\n"
f"Estrazioni: {len(date):,}\n"
f"Ruote : 11 (inclusa Nazionale)\n"
f"Trovate : {totale:,} coppie\n"
f"{'='*58}\n"
f"{'Pos':>8} {'Ambo 1':>7} {'Ambo 2':>7} {'Rit.Max':>8} {'Rit.Att':>8}\n"
f"{'-'*54}\n"
)
os.makedirs(os.path.dirname(OUTPUT), exist_ok=True)
with open(OUTPUT, "w", encoding="utf-8") as f:
f.write(header)
for r in righe:
f.write(r.strip() + "\n")
print(f" File generale salvato: {OUTPUT}")
header_sfaldati = (
f"BIAMBI CON STORICO <= {SOGLIA} SFALDATI NELL'ULTIMA ESTRAZIONE DEL {fmt(date[-1])}\n"
f"Trovati : {len(righe_sfaldate):,} biambi sfaldati su {totale:,} totali\n"
f"{'='*58}\n"
f"{'Pos':>8} {'Ambo 1':>7} {'Ambo 2':>7} {'Rit.Max':>8} {'Rit.Att':>8}\n"
f"{'-'*54}\n"
)
with open(OUTPUT_SFALDATI, "w", encoding="utf-8") as f_sf:
f_sf.write(header_sfaldati)
for r in righe_sfaldate:
f_sf.write(r.strip() + "\n")
print(f" [NOVITÀ] File sfaldati ultima estrazione salvato: {OUTPUT_SFALDATI}")
print(f" Biambi storici sfaldati nell'ultimo concorso: {len(righe_sfaldate):,}")
return totale
def main():
print("╔══════════════════════════════════════════════════════════════╗")
print("║ BIAMBI CON RITARDO MAX STORICO <= SOGLIA — LOTTO ║")
print("║ (11 ruote inclusa Nazionale - dal ID 8117) ║")
print("╚══════════════════════════════════════════════════════════════╝\n")
if not os.path.exists(ARCHIVIO):
print(f"[ERRORE] Archivio non trovato in: {ARCHIVIO}")
print("Metti il file 'estrazioni.csv' nella stessa cartella dello script!")
input("\nPremi INVIO per uscire...")
sys.exit(1)
print(f" Lettura archivio: {ARCHIVIO}")
print(f" ID inizio : {ID_INIZIO}")
arr, date = leggi_archivio(ARCHIVIO)
print(f" Righe lette: {len(date):,} ({fmt(date[0])} → {fmt(date[-1])})")
ambo_i_arr, ambo_j_arr = build_arrays()
rit_max, rit_att, ultimi_ambi_usciti = calcola(arr, ambo_i_arr, ambo_j_arr)
totale = salva(rit_max, rit_att, date, ultimi_ambi_usciti)
print(f"\n Coppie totali : {NUM_COPPIE:,}")
print(f" Coppie <= {SOGLIA} : {totale:,}")
print(f" Percentuale : {totale/NUM_COPPIE*100:.4f}%")
print("\n Arrivederci!")
input("\nPremi INVIO per chiudere il programma...")
if __name__ == "__main__":
main()
prima in qualche modo sono riuscito a crearlo così
2605202637357451187217290188397842526244303760011829670286608747695172263476180331208439822374767079683387034663024171
Se ora puoi indicare come vanno impostate le virgole penso ok ogni estratto ma la data come va gestita?
26052026, è poi gli estratti. Se puoi aiutarmi a capire ti ringrazio fin da ora e grazie comunque per quanto hai proposto con questa nuova interfaccia da utilizzare per il lotto
AMBO A TUTTE + NZ SU TUTTE LE CINQUINE . DOVRA GIRARE PER QULCHE GIORNO .
Codice:
"""
CINQUINE C(90,5) — RITARDO MASSIMO STORICO <= 79
==================================================
Genera tutte le 43.949.268 cinquine e trova quelle
con ritardo massimo storico <= SOGLIA.
Una cinquina si azzera se almeno uno dei 10 ambi C(5,2)
che la compongono esce su qualsiasi delle 11 ruote.
Memoria stimata: ~400 MB
Tempo stimato : 30-60 minuti
Struttura Archivio.txt:
ggmmaaaa + 110 cifre, 11 ruote x 5 numeri x 2 cifre
ID_INIZIO = 8117 (inclusa Nazionale)
"""
import os
import sys
import time
import numpy as np
from itertools import combinations
ARCHIVIO = r"C:\Users\HP\AppData\Roaming\spaziometria\ArcTlv\Archivio.txt"
OUTPUT = r"C:\Users\HP\Desktop\cinquine_sotto79.xlsx"
SOGLIA = 79
ID_INIZIO = 8117
NUM_RUOTE = 11
NUM_ESTRATTI = 5
COMBO_5_2 = list(combinations(range(NUM_ESTRATTI), 2))
def ambo_idx(a, b):
if a > b: a, b = b, a
return (a - 1) * 90 - a * (a - 1) // 2 + (b - a - 1)
def fmt(d): return f"{d[:2]}/{d[2:4]}/{d[4:]}"
# ─────────────────────────────────────────────
# LETTURA ARCHIVIO
# ─────────────────────────────────────────────
def leggi_archivio(path):
estrazioni, date = [], []
with open(path, "r", encoding="utf-8") as f:
for lineno, line in enumerate(f, 1):
line = line.strip()
if not line: continue
if len(line) < 118: continue
if lineno < ID_INIZIO: continue
data, cifre = line[:8], line[8:118]
ruote = []
for r in range(11):
off = r * NUM_ESTRATTI * 2
nums = []
for e in range(NUM_ESTRATTI):
try: nums.append(int(cifre[off + e*2 : off + e*2 + 2]))
except: nums.append(0)
ruote.append(nums)
date.append(data)
estrazioni.append(ruote)
return estrazioni, date
# ─────────────────────────────────────────────
# GENERAZIONE CINQUINE
# ─────────────────────────────────────────────
def genera_cinquine():
print(" Generazione cinquine C(90,5)...", end=" ", flush=True)
t0 = time.time()
# Array shape (43_949_268, 5) dtype uint8
N = 43_949_268
arr = np.empty((N, 5), dtype=np.uint8)
idx = 0
for a in range(1, 91):
for b in range(a+1, 91):
for c in range(b+1, 91):
for d in range(c+1, 91):
for e in range(d+1, 91):
arr[idx] = [a, b, c, d, e]
idx += 1
print(f"fatto in {time.time()-t0:.1f}s ({idx:,} cinquine)")
return arr
# ─────────────────────────────────────────────
# CALCOLO
# ─────────────────────────────────────────────
def calcola(estrazioni, cinquine):
N = len(estrazioni)
M = len(cinquine)
print(f"\n Estrazioni : {N:,} (dal ID {ID_INIZIO})")
print(f" Cinquine : {M:,}")
print(f" Ruote : {NUM_RUOTE}")
print(f" Soglia : <= {SOGLIA}\n")
rit_cor = np.zeros(M, dtype=np.uint16)
rit_max = np.zeros(M, dtype=np.uint16)
# Colonne separate per accesso vettoriale veloce
col = [cinquine[:, i] for i in range(5)]
t0 = time.time()
for idx_e, ruote in enumerate(estrazioni):
if idx_e % 100 == 0:
el = time.time() - t0
pct = idx_e / N * 100
eta = (el / (idx_e + 1)) * (N - idx_e) if idx_e > 0 else 0
print(f" [{idx_e:5,}/{N:,}] {pct:.1f}% ETA: {eta:.0f}s ", end="\r")
# Numeri usciti su tutte le ruote (set unico)
numeri_usciti = set()
ambi_usciti = set()
for r in range(NUM_RUOTE):
nums = ruote[r]
for c1, c2 in COMBO_5_2:
a, b = nums[c1], nums[c2]
if a > 0 and b > 0:
ambi_usciti.add((min(a,b), max(a,b)))
numeri_usciti.add(a)
numeri_usciti.add(b)
if not ambi_usciti:
rit_cor += 1
continue
# Maschera vettoriale:
# Una cinquina si azzera se contiene entrambi i numeri
# di almeno un ambo uscito
mask = np.zeros(M, dtype=bool)
for (x, y) in ambi_usciti:
# Cinquine che contengono x
has_x = ((col[0] == x) | (col[1] == x) | (col[2] == x) |
(col[3] == x) | (col[4] == x))
# Cinquine che contengono y
has_y = ((col[0] == y) | (col[1] == y) | (col[2] == y) |
(col[3] == y) | (col[4] == y))
# Cinquine che contengono ENTRAMBI
mask |= (has_x & has_y)
# Aggiorna max e azzera
rit_max[mask] = np.maximum(rit_max[mask], rit_cor[mask])
rit_cor[mask] = 0
rit_cor += 1
# Fine archivio
np.maximum(rit_max, rit_cor, out=rit_max)
print(f"\n Completato in {time.time()-t0:.1f}s")
return rit_max, rit_cor
# ─────────────────────────────────────────────
# OUTPUT EXCEL
# ─────────────────────────────────────────────
def salva_excel(cinquine, rit_max, rit_att, date):
try:
from openpyxl import Workbook
from openpyxl.styles import Font, PatternFill, Alignment, Border, Side
from openpyxl.utils import get_column_letter
except ImportError:
print("\n [ERRORE] Installa openpyxl: pip install openpyxl")
return
print(f"\n Filtro cinquine con rit_max <= {SOGLIA}...")
idx_ok = np.where(rit_max <= SOGLIA)[0]
ord_key = np.lexsort((-rit_att[idx_ok], rit_max[idx_ok]))
idx_ok = idx_ok[ord_key]
totale = len(idx_ok)
print(f" Cinquine trovate: {totale:,}")
print(f" Creazione file Excel...")
wb = Workbook()
ws1 = wb.active
ws1.title = f"Max <= {SOGLIA}"
header_fill = PatternFill("solid", fgColor="1F4E79")
header_font = Font(bold=True, color="FFFFFF", size=11)
thin = Side(style="thin", color="CCCCCC")
border = Border(left=thin, right=thin, top=thin, bottom=thin)
fill_alt = PatternFill("solid", fgColor="EBF3FB")
headers = ["Pos", "N1", "N2", "N3", "N4", "N5", "Rit.Max", "Rit.Att"]
col_w = [8, 6, 6, 6, 6, 6, 10, 10]
for col, (h, w) in enumerate(zip(headers, col_w), 1):
cell = ws1.cell(row=1, column=col, value=h)
cell.font = header_font
cell.fill = header_fill
cell.alignment = Alignment(horizontal="center", vertical="center")
cell.border = border
ws1.column_dimensions[get_column_letter(col)].width = w
ws1.row_dimensions[1].height = 20
ws1.freeze_panes = "A2"
ws1.auto_filter.ref = f"A1:{get_column_letter(len(headers))}1"
thin2 = Side(style="thin", color="CCCCCC")
border2 = Border(left=thin2, right=thin2, top=thin2, bottom=thin2)
for rank, k in enumerate(idx_ok, 1):
a, b, c, d, e = [int(x) for x in cinquine[k]]
mx = int(rit_max[k])
att = int(rit_att[k])
row_data = [rank, a, b, c, d, e, mx, att]
fill = fill_alt if rank % 2 == 0 else None
for col, val in enumerate(row_data, 1):
cell = ws1.cell(row=rank+1, column=col, value=val)
cell.alignment = Alignment(horizontal="center")
cell.border = border2
if fill:
cell.fill = fill
wb.save(OUTPUT)
print(f" File Excel salvato : {OUTPUT}")
print(f" Cinquine trovate : {totale:,} su {len(cinquine):,}")
return totale
# ─────────────────────────────────────────────
# MAIN
# ─────────────────────────────────────────────
def main():
print("╔══════════════════════════════════════════════════════════════╗")
print("║ CINQUINE C(90,5) — RITARDO MAX <= 79 — LOTTO ║")
print("║ (11 ruote inclusa Nazionale - dal ID 8117) ║")
print("╚══════════════════════════════════════════════════════════════╝\n")
if not os.path.exists(ARCHIVIO):
print(f"[ERRORE] Archivio non trovato: {ARCHIVIO}")
sys.exit(1)
print(f" Lettura archivio dal ID {ID_INIZIO}...")
estrazioni, date = leggi_archivio(ARCHIVIO)
print(f" Estrazioni lette: {len(date):,} ({fmt(date[0])} → {fmt(date[-1])})")
cinquine = genera_cinquine()
rit_max, rit_att = calcola(estrazioni, cinquine)
salva_excel(cinquine, rit_max, rit_att, date)
print("\n Arrivederci!")
if __name__ == "__main__":
main()Cinzia chi lo puo' dire ? I ritardi sono fatti per essere superati in base al numero delle estrazioni nel senso che all' aumenatre del numero di estrazioni in archivio anche i ritardi max tendono ad aumentare . Forse occorre raggruppare gli ambi in base a criteri specifici.Ciao, Acquafresca, Genios e quanti seguono il 3D
1.4;3.25;32.64 mx st 33 at 16
Ritenete che si possa superare?
joe
Advanced Member >PLATINUM PLUS<
Ciao, Acquafresca, ho provato a far girare il file precedente, direi un buon lavoro e sopratutto veloce rispetto alla velocità in spaziometria, ora hai postato questo giustamente adattato al tuo archivio ma non ho capito comè è realizzato, a prte csv parli di virgole su ogni estratto compreso le date, per capirne la logica e vedere cosa sviluppa.
prima in qualche modo sono riuscito a crearlo così
2605202637357451187217290188397842526244303760011829670286608747695172263476180331208439822374767079683387034663024171
Se ora puoi indicare come vanno impostate le virgole penso ok ogni estratto ma la data come va gestita?
26052026, è poi gli estratti. Se puoi aiutarmi a capire ti ringrazio fin da ora e grazie comunque per quanto hai proposto con questa nuova interfaccia da utilizzare per il lotto
Penso che l'archivio a cui far riferire un programma debba avere una sorta di precedenza sugli script che lo usano.
Quello a cui vi riferite era stato creato appositamente per aggiornare spaziometria dopo averlo scaricato dal sito di Silop.
Silop lo aggiornava regolarmente ad ogni estrazione con uno script apposito che prelevava l'ultima estrazione dal televideo e l'aggiungeva.
Il formato è 2 cifre per il Giorno, 2 Cifre per il mese, 4 Cifre per l'Anno e 2 Cifre per ognuno dei 55 Estratti.
Python invece, la data la considera alla rovescia di noi europei. Cioè antepone l' Anno, mettendolo PRIMA del Mese e del Giorno.
Tempo fa avevo scritto a Silop considerando opportuno che si potesse modificare la struttura di questo archivio testuale
che avevamo creato, assieme alla cartella ArcTlv, che si generava nell' eseguire lo script per aggiornare Spaziometria.
Poi però, in ultimo, questa procedura di aggiornamento fu superata dalle routine che LuigiB aggiunse all'ultima versione di Spaziometria.
Ora in qualche modo state cercando di utilizzarlo, ma secondo il mio modesto parere andrebbe preventivamente stabilito
un odine procedurale per evitare di disperdere le risorse in 1000 rivoli tutti simili tra loro e poi incompatibili gli uni con gli altri.
")
Si aggiorna con il programma spaziometria for ever .Penso che l'archivio a cui far riferire un programma debba avere una sorta di precedenza sugli script che lo usano.
Quello a cui vi riferite era stato creato appositamente per aggiornare spaziometria dopo averlo scaricato dal sito di Silop.
Silop lo aggiornava regolarmente ad ogni estrazione con uno script apposito che prelevava l'ultima estrazione dal televideo e l'aggiungeva.
Il formato è 2 cifre per il Giorno, 2 Cifre per il mese, 4 Cifre per l'Anno e 2 Cifre per ognuno dei 55 Estratti.
Python invece, la data la considera alla rovescia di noi europei. Cioè antepone l' Anno, mettendolo PRIMA del Mese e del Giorno.
Tempo fa avevo scritto a Silop considerando opportuno che si potesse modificare la struttura di questo archivio testuale
che avevamo creato, assieme alla cartella ArcTlv, che si generava nell' eseguire lo script per aggiornare Spaziometria.
Poi però, in ultimo, questa procedura di aggiornamento fu superata dalle routine che LuigiB aggiunse all'ultima versione di Spaziometria.
Ora in qualche modo state cercando di utilizzarlo, ma secondo il mio modesto parere andrebbe preventivamente stabilito
un odine procedurale per evitare di disperdere le risorse in 1000 rivoli tutti simili tra loro e poi incompatibili gli uni con gli altri.
Lottopython
Advanced Member >PLATINUM<
Ciao @joe ,
Python esegue degli ordini precisi o disastrosi a volte(bisogna anche fare in modo di saperglieli dare questi ultimi), indipendentemente dalla formattazione in lettura se hai una formattazione in arichivo (YYYY/MM/DD 55numeri) puoi dirgli di in fase di compilazione qualsiasi tipo di formattazione e/o modifica e poi dirgli come leggere quella stringa o quell'insieme e come modificarla prima di poterne usufruire in fase di verifica ,non ha importanza alcuna la formattazione iniziale dell'archivio ,la lettura dei dati e/o la trasformazione prima di leggere l'archivio puo' esser decisa in fase di costruzione del programma stesso . buon proseguimento.
Python esegue degli ordini precisi o disastrosi a volte(bisogna anche fare in modo di saperglieli dare questi ultimi), indipendentemente dalla formattazione in lettura se hai una formattazione in arichivo (YYYY/MM/DD 55numeri) puoi dirgli di in fase di compilazione qualsiasi tipo di formattazione e/o modifica e poi dirgli come leggere quella stringa o quell'insieme e come modificarla prima di poterne usufruire in fase di verifica ,non ha importanza alcuna la formattazione iniziale dell'archivio ,la lettura dei dati e/o la trasformazione prima di leggere l'archivio puo' esser decisa in fase di costruzione del programma stesso . buon proseguimento.
joe
Advanced Member >PLATINUM PLUS<
OK.
Nel discorso tra Acquafresca e Xerox c'è un riferimento alla struttura dell'Archivio ed alla possibilità di ri-considerarlo in formato csv.
Ho fornito dettagli riguardo a quella dell'archivio qui utilizzato per il programma che Eugenio ha dato a Cinzia.
Ovviamente, nelle tue Routine di aggiornamento, come avevi scritto, crei una copia, di quello testuale qui utilizzato.
Esso ha una estrazione per ogni riga nel formato che Xerox ha creato per l'Estrazione del 26 maggio 2026
e che corrisponde esattamente a quanto da me descritto.
In csv forse sarebbe meglio separare i componenti della data (tra di loro) e dagli estratti.
Nel discorso tra Acquafresca e Xerox c'è un riferimento alla struttura dell'Archivio ed alla possibilità di ri-considerarlo in formato csv.
Ho fornito dettagli riguardo a quella dell'archivio qui utilizzato per il programma che Eugenio ha dato a Cinzia.
Ovviamente, nelle tue Routine di aggiornamento, come avevi scritto, crei una copia, di quello testuale qui utilizzato.
Esso ha una estrazione per ogni riga nel formato che Xerox ha creato per l'Estrazione del 26 maggio 2026
e che corrisponde esattamente a quanto da me descritto.
In csv forse sarebbe meglio separare i componenti della data (tra di loro) e dagli estratti.
Acquafresca
Super Member >PLATINUM<
Grazie Xeroxs, riguardo alle virgolette intendevo quelle che vedi all'inizio dello script e cioè questeCiao, Acquafresca, ho provato a far girare il file precedente, direi un buon lavoro e sopratutto veloce rispetto alla velocità in spaziometria, ora hai postato questo giustamente adattato al tuo archivio ma non ho capito comè è realizzato, a prte csv parli di virgole su ogni estratto compreso le date, per capirne la logica e vedere cosa sviluppa.
prima in qualche modo sono riuscito a crearlo così
2605202637357451187217290188397842526244303760011829670286608747695172263476180331208439822374767079683387034663024171
Se ora puoi indicare come vanno impostate le virgole penso ok ogni estratto ma la data come va gestita?
26052026, è poi gli estratti. Se puoi aiutarmi a capire ti ringrazio fin da ora e grazie comunque per quanto hai proposto con questa nuova interfaccia da utilizzare per il lotto
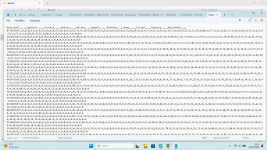
 """).poi il formato dell'archivio < estrazioni.csv > è impostato come vedrai lo screenshot allegato,con l'IA e python che inizialmente non riusciva a leggero facendo la forzatura adesso lo riconosce senza errori, premetto che per aggiornarlo uso altro piccolo programmino sempre creato con python che lo aggiorna col copia/incolla
""").poi il formato dell'archivio < estrazioni.csv > è impostato come vedrai lo screenshot allegato,con l'IA e python che inizialmente non riusciva a leggero facendo la forzatura adesso lo riconosce senza errori, premetto che per aggiornarlo uso altro piccolo programmino sempre creato con python che lo aggiorna col copia/incollaCiao, Acquafresca, ho provato a far girare il file precedente, direi un buon lavoro e sopratutto veloce rispetto alla velocità in spaziometria, ora hai postato questo giustamente adattato al tuo archivio ma non ho capito comè è realizzato, a prte csv parli di virgole su ogni estratto compreso le date, per capirne la logica e vedere cosa sviluppa.
prima in qualche modo sono riuscito a crearlo così
2605202637357451187217290188397842526244303760011829670286608747695172263476180331208439822374767079683387034663024171
Se ora puoi indicare come vanno impostate le virgole penso ok ogni estratto ma la data come va gestita?
26052026, è poi gli estratti. Se puoi aiutarmi a capire ti ringrazio fin da ora e grazie comunque per quanto hai proposto con questa nuova interfaccia da utilizzare per il lott
Allegati
joe
Advanced Member >PLATINUM PLUS<
Acquafresca, ti tingrazio per il commento e le considerazioni al rigurdo.
Come vedi l'output che hai proposto alterna, valori interi (Integer) e decimali (Float).
Questo non è gradito agli interpreti/compilatori dello script e più ancora nel Python.
Mentre lo script di Eugenio, riesce a dividerli a 2 a 2, ovvero leggendo "una decina + una unità",
perché le stringhe/estrazione hanno tutte la stessa lunghezza che avevo definito:
8 per la data (2 giorno + 2 mese + 4 anno) + 55 * 2 caratteri = 118 caratteri.
Il Basic di spaziometria "sa" quante estrazioni ci sono nel file (con UBound) dunque non è indispensabile numerarle in archivio.
In alcuni vecchi programmi ci sono dei limiti per l'archivio (ad esempio 8000 estrazioni) ed oggi è difficoltoso aggiornarli.
Come vedi l'output che hai proposto alterna, valori interi (Integer) e decimali (Float).
Questo non è gradito agli interpreti/compilatori dello script e più ancora nel Python.
Mentre lo script di Eugenio, riesce a dividerli a 2 a 2, ovvero leggendo "una decina + una unità",
perché le stringhe/estrazione hanno tutte la stessa lunghezza che avevo definito:
8 per la data (2 giorno + 2 mese + 4 anno) + 55 * 2 caratteri = 118 caratteri.
Il Basic di spaziometria "sa" quante estrazioni ci sono nel file (con UBound) dunque non è indispensabile numerarle in archivio.
In alcuni vecchi programmi ci sono dei limiti per l'archivio (ad esempio 8000 estrazioni) ed oggi è difficoltoso aggiornarli.
Katia-Serra-Ippoliti
Advanced Member >PLATINUM PLUS<
In effetti una Cinquina genera 10 ambi ( Decambo ) il problema è che nello sviluppo dei 10 Ambi ci saranno sempre 4 numeri uguali della cinquina madre.Forse per i 10 ambi occorrerebbe fare una ricerca su tutte le milioni di cinquine ,
Possiamo chiamarli Decambi Derivati, al momento sono 2 le Cinquina a Storico Minimo per Ambo con valore = a ( 13 ) su Tutte & Nazionale dalla 8117:
1) #--- [ 06;10;25;61;89 ] max-st = 13 Attuale = 06
2) #--- [ 09;28;31;33;75 ] Max-st = 13 Attuale = 03
----------------------------------------------------------------------
Controllare sempre la veridicità dei dati...
Katia
STRUTTURA DELL’ARCHIVIO (Archivio.txt)Ciao @joe ,
Python esegue degli ordini precisi o disastrosi a volte(bisogna anche fare in modo di saperglieli dare questi ultimi), indipendentemente dalla formattazione in lettura se hai una formattazione in arichivo (YYYY/MM/DD 55numeri) puoi dirgli di in fase di compilazione qualsiasi tipo di formattazione e/o modifica e poi dirgli come leggere quella stringa o quell'insieme e come modificarla prima di poterne usufruire in fase di verifica ,non ha importanza alcuna la formattazione iniziale dell'archivio ,la lettura dei dati e/o la trasformazione prima di leggere l'archivio puo' esser decisa in fase di costruzione del programma stesso . buon proseguimento.
Percorso:
C:\Users\HP\AppData\Roaming\spaziometria\ArcTlv\Archivio.txt
Ogni riga è composta così:
ggmmaaaa <110 cifre (11 ruote × 10 numeri ciascuna)>
Esempio (semplificato):
03112011 011422385970... [continua fino a 110 cifre]
Quindi ogni estrazione ha:
- 11 ruote × 5 numeri = 55 numeri → 110 cifre
- Da leggere a coppie di due cifre (es. 01, 14, 22, 38, 59, …)
QUESTA è UNA RIGA DELL’ ARCHIVIO
2511202506331487739073483567206686792739552374608634231851011260118241788871746677245311109035774847798205658814154809
L’ARCHIVIO INIZIA CON ID = 1
joe
Advanced Member >PLATINUM PLUS<
Codice:
def leggi_archivio(path):
estrazioni, date = [], []
with open(path, "r", encoding="utf-8") as f:
for lineno, line in enumerate(f, 1):
line = line.strip()
if not line: continue
if len(line) < 118:
print(f" [WARN] riga {lineno} corta, saltata.")
continue
# Salta le estrazioni prima di ID_INIZIO
if lineno < ID_INIZIO:
continue
data, cifre = line[:8], line[8:118]
ruote = []
for r in range(11): # legge tutte e 11
off = r * NUM_ESTRATTI * 2
nums = []
for e in range(NUM_ESTRATTI):
try: nums.append(int(cifre[off + e*2 : off + e*2 + 2]))
except: nums.append(0)
ruote.append(nums)
date.append(data)
estrazioni.append(ruote)
return np.array(estrazioni, dtype=np.int16), dateEugenio, non sono esperto di Python ma come ho già scritto diverse volte quel file-archivio l'ho deciso io che struttura avesse.
Pertanto in quell'archivio ogni riga ha 118 caratteri.
certo 110 caratteri i numeri 8 la dataCodice:def leggi_archivio(path): estrazioni, date = [], [] with open(path, "r", encoding="utf-8") as f: for lineno, line in enumerate(f, 1): line = line.strip() if not line: continue if len(line) < 118: print(f" [WARN] riga {lineno} corta, saltata.") continue # Salta le estrazioni prima di ID_INIZIO if lineno < ID_INIZIO: continue data, cifre = line[:8], line[8:118] ruote = [] for r in range(11): # legge tutte e 11 off = r * NUM_ESTRATTI * 2 nums = [] for e in range(NUM_ESTRATTI): try: nums.append(int(cifre[off + e*2 : off + e*2 + 2])) except: nums.append(0) ruote.append(nums) date.append(data) estrazioni.append(ruote) return np.array(estrazioni, dtype=np.int16), date
Eugenio, non sono esperto di Python ma come ho già scritto diverse volte quel file-archivio l'ho deciso io che struttura avesse.
Pertanto in quell'archivio ogni riga ha 118 caratteri.
") e si aggiorna con spaziometria for ever fino ad ora .
e si aggiorna con spaziometria for ever fino ad ora .Buonasera Katia, ho controllato i decambi che hai postato e risultano esatti fino all'estrazione del 26/05/2026 partendo dalla ( 8117 ).In effetti una Cinquina genera 10 ambi ( Decambo ) il problema è che nello sviluppo dei 10 Ambi ci saranno sempre 4 numeri uguali della cinquina madre.
Possiamo chiamarli Decambi Derivati, al momento sono 2 le Cinquina a Storico Minimo per Ambo con valore = a ( 13 ) su Tutte & Nazionale dalla 8117:
1) #--- [ 06;10;25;61;89 ] max-st = 13 Attuale = 06
2) #--- [ 09;28;31;33;75 ] Max-st = 13 Attuale = 03
----------------------------------------------------------------------
Controllare sempre la veridicità dei dati...
Katia
Guarda caso questa sera il decambo a ritardo 6 ha fatto bingo! Ambo 06-89 su Palermo, una delle 3 ruote più ritardate.
Sei Mitica
")
Sono sicuro che avrai anche gli storici per i triambi e sicuramente per i decambi.
Complimenti.
sandro
Katia-Serra-Ippoliti
Advanced Member >PLATINUM PLUS<
Ciao Sandro anche se non è farina del mio sacco sugli storici ho qualcosa.
per i triambi altro bingo con uno storico max- = a ( 32 )
Per i decambi il discorso si fa più complicato , avevo giorni fa menzionato in altra sezione quante fossero le iterazioni da compiere per sfogliare i Decambi! nessuno era intervenuto e pazienza. ( non credo ci sia qualcuno attualmente in grado oltre alle chiacchiere ; che riesca a portare a termine l'elaborazione integrale sui Decambi ) è cosa da esperti e professionisti della Programmazione.
Anche se è possibile aggirare l'ostacolo e scendere da valore ( 14 ) in effetti i 2 decambi che ho postato con 4 numeri uguali si attestano a valore ( 13 ) dove di decambi integrali ce ne sono a milionate a questo valore...
Grazie per la tua gentilezza, ci vidiamo nell'altra sezione.
Katia
per i triambi altro bingo con uno storico max- = a ( 32 )
Per i decambi il discorso si fa più complicato , avevo giorni fa menzionato in altra sezione quante fossero le iterazioni da compiere per sfogliare i Decambi! nessuno era intervenuto e pazienza. ( non credo ci sia qualcuno attualmente in grado oltre alle chiacchiere ; che riesca a portare a termine l'elaborazione integrale sui Decambi ) è cosa da esperti e professionisti della Programmazione.
Anche se è possibile aggirare l'ostacolo e scendere da valore ( 14 ) in effetti i 2 decambi che ho postato con 4 numeri uguali si attestano a valore ( 13 ) dove di decambi integrali ce ne sono a milionate a questo valore...
Grazie per la tua gentilezza, ci vidiamo nell'altra sezione.
Katia
Buonasera Katia, altro giro altro bingo.In effetti una Cinquina genera 10 ambi ( Decambo ) il problema è che nello sviluppo dei 10 Ambi ci saranno sempre 4 numeri uguali della cinquina madre.
Possiamo chiamarli Decambi Derivati, al momento sono 2 le Cinquina a Storico Minimo per Ambo con valore = a ( 13 ) su Tutte & Nazionale dalla 8117:
1) #--- [ 06;10;25;61;89 ] max-st = 13 Attuale = 06
2) #--- [ 09;28;31;33;75 ] Max-st = 13 Attuale = 03
----------------------------------------------------------------------
Controllare sempre la veridicità dei dati...
Katia
Il primo decambo ripete a colpo un Ambo su Roma immagino che sui decambi che avevi citati a valore 13 ne saranno usciti parecchi.
Buon ponte di feste.
sandro
Acquafresca
Super Member >PLATINUM<
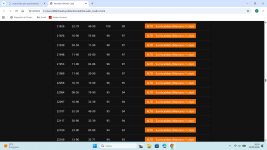
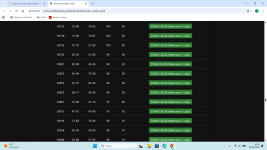
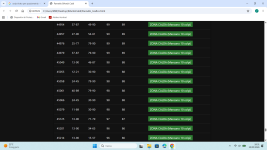
Altra prova molto più semplice e veloce con C++ (da completare ad programmino) analisi a partire dal concorso 7440 dalla 1à estrazione della ruota Nazionale conun tempo di analisi finale di 527.03 secondi (circa 9 minuti) con questi stupendi risultatiCiao, Acquafresca, Genios e quanti seguono il 3D
1.4;3.25;32.64 mx st 33 at 16
Ritenete che si possa superare?
Allegati
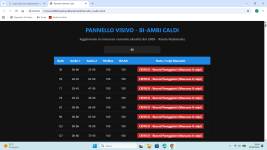
Ultima modifica:
Katia, questa sera al 3^ colpo Triplete anzi Quadriplete.In effetti una Cinquina genera 10 ambi ( Decambo ) il problema è che nello sviluppo dei 10 Ambi ci saranno sempre 4 numeri uguali della cinquina madre.
Possiamo chiamarli Decambi Derivati, al momento sono 2 le Cinquina a Storico Minimo per Ambo con valore = a ( 13 ) su Tutte & Nazionale dalla 8117:
1) #--- [ 06;10;25;61;89 ] max-st = 13 Attuale = 06
2) #--- [ 09;28;31;33;75 ] Max-st = 13 Attuale = 03
----------------------------------------------------------------------
Controllare sempre la veridicità dei dati...
Katia
Sempre il primo decambo con 25-61 a Bari e 25-89 a Napoli.
Le tue analisi sono sempre chiare e sintetiche, complimenti.
sandro
Ultima estrazione Lotto
-
Estrazione del lotto
martedì 14 luglio 2026Bari4866097835Cagliari5152153872Firenze0860782025Genova4602052281Milano2968755324Napoli8412138169Palermo2818025438Roma3607724516Torino7631735520Venezia5451422649Nazionale0375640907Estrazione Simbolotto
Nazionale



 1441290724
1441290724