Lottopython
Advanced Member >PLATINUM<
a voi ulterirori approfondimenti
questo ne è un esempio k.fold nelle varie fasi di addestramento
1. adam.mse
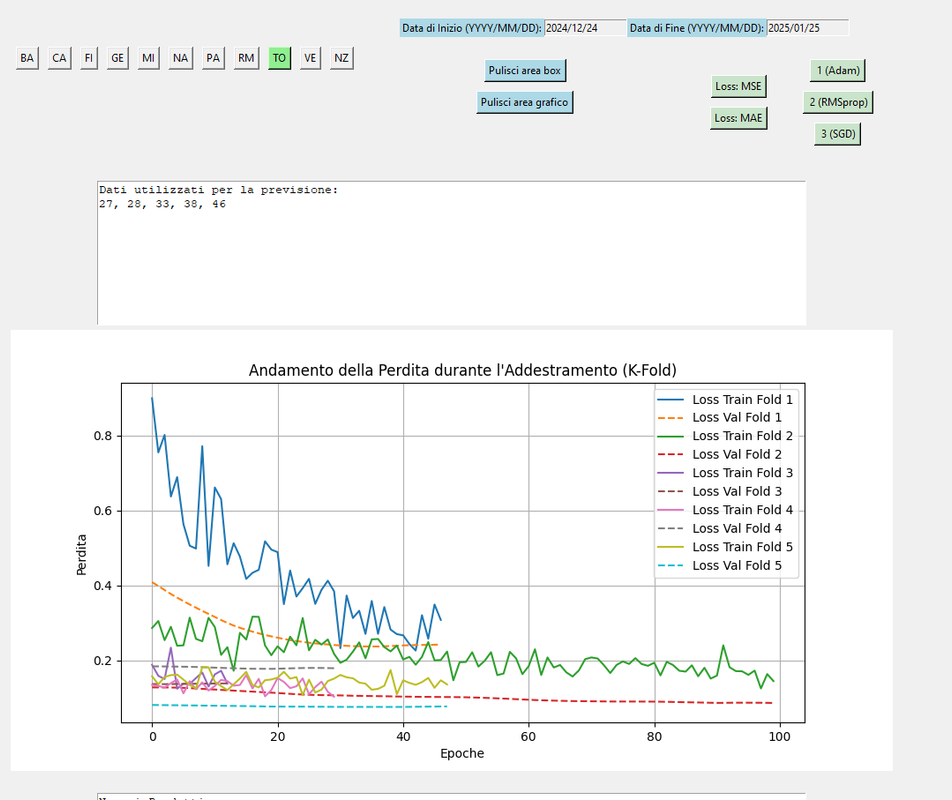
RMSPROP/MSE
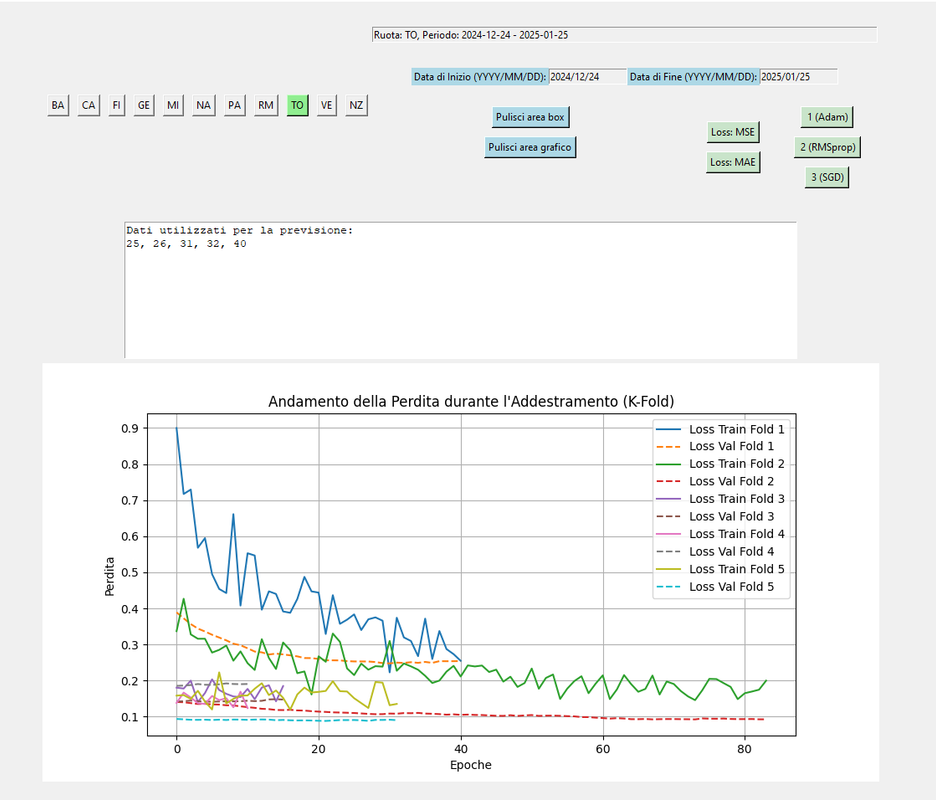
SGD. MSE
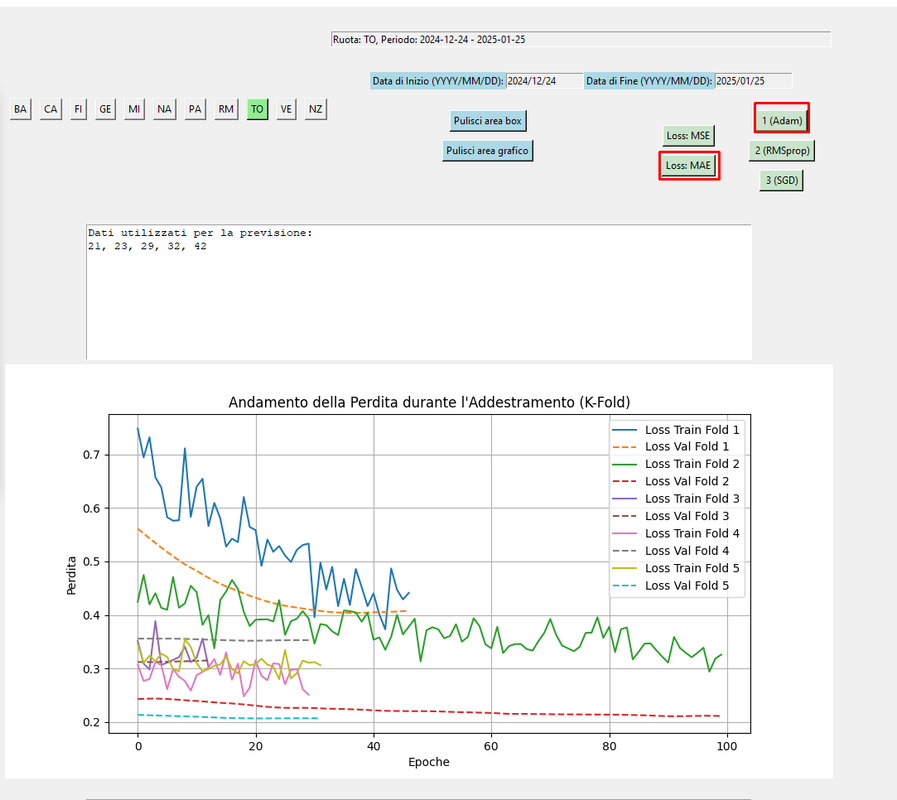
QUI SI CAMBIA ADAM.MAE
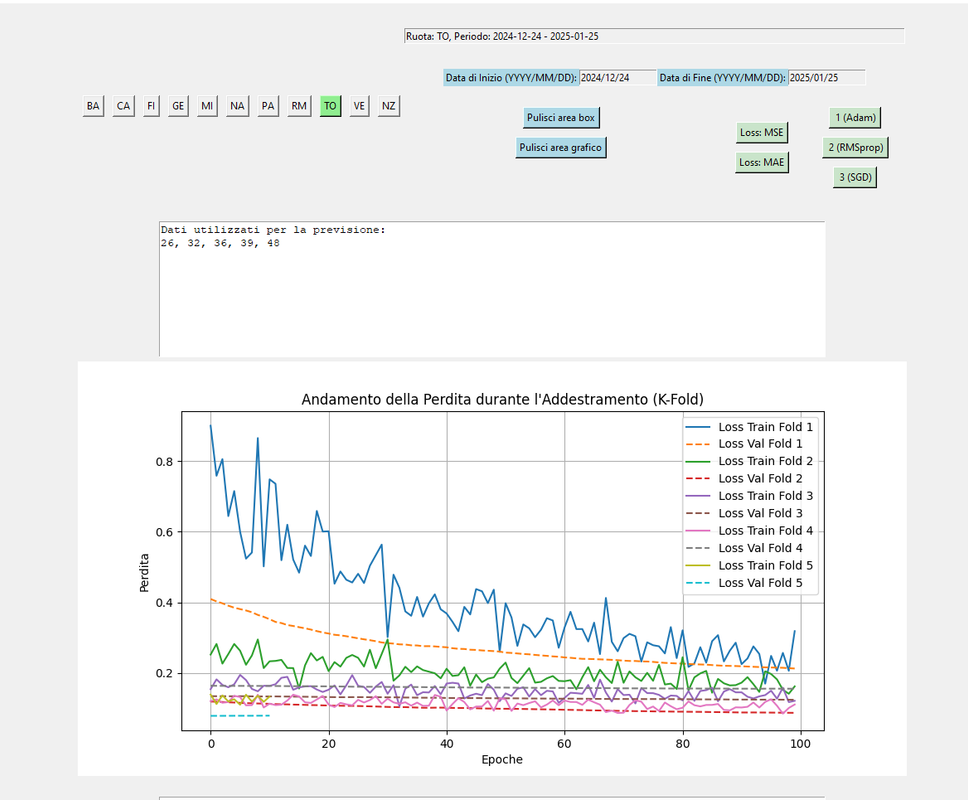
RMSPORP.MAE
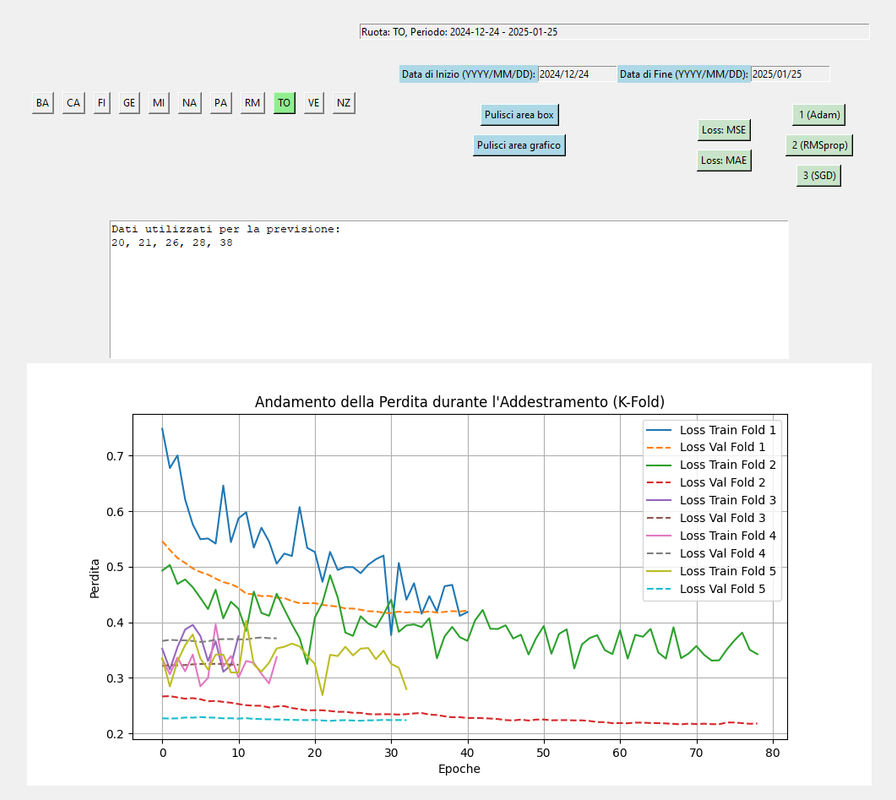
QUESTA A MIO AVVISO LA MIGLIORA CONDIZIONE DI APPRENDIMENTO
SGD MAE
questo ne è un esempio k.fold nelle varie fasi di addestramento
1. adam.mse
RMSPROP/MSE
SGD. MSE
QUI SI CAMBIA ADAM.MAE
RMSPORP.MAE
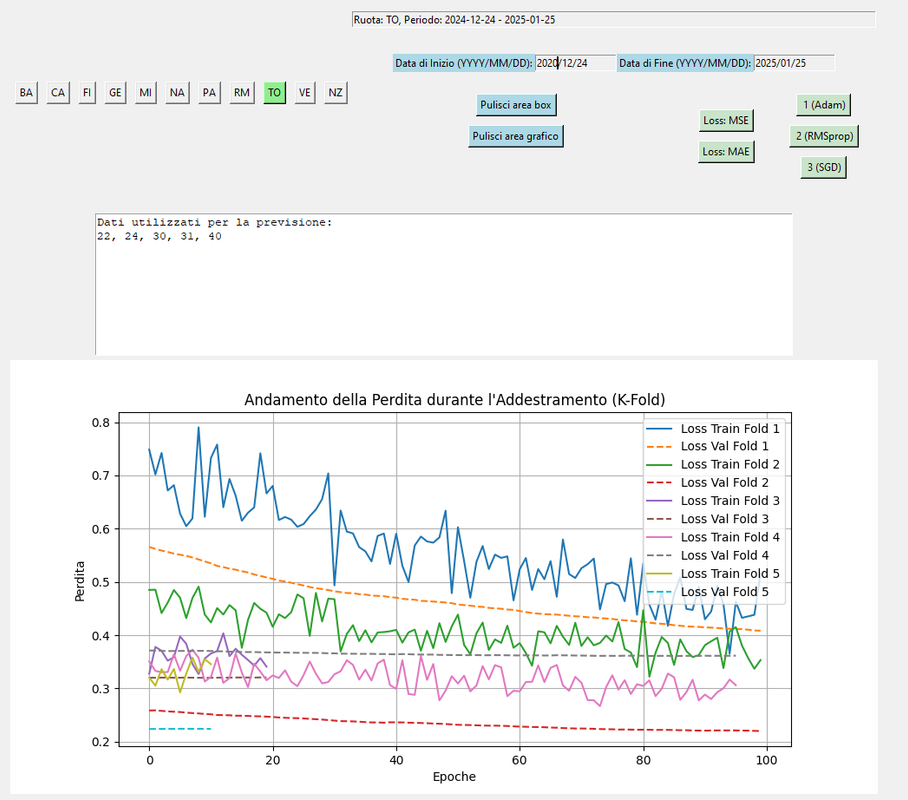
QUESTA A MIO AVVISO LA MIGLIORA CONDIZIONE DI APPRENDIMENTO
SGD MAE
La combinazione SGD (Stochastic Gradient Descent) con la funzione di perdita Mean Absolute Error (MAE) è una scelta comune in apprendimento automatico, soprattutto quando si lavora con dati che presentano un grande spazio di valori possibili per le features e per le etichette.
Perché SGD?
- Efficienti: SGD è un algoritmo di ottimizzazione efficiente, specialmente quando si lavora con grandi insiemi di dati. La sua esecuzione è lineare rispetto alla dimensione del dataset, il che significa che può gestire facilmente milioni di esempi di training.
- Robustezza: SGD è un algoritmo robusto, in quanto può funzionare bene anche con piccoli batch di dati. Ciò è particolarmente utile quando non si dispone di un grande batch di dati da addestrare.
- Flessibilità: SGD può essere utilizzato sia in modo batch (con grandi batch) che online (con singoli esempi). Ciò gli consente di adattarsi a diversi scenari.
Perché MAE?
- Sensibilità ai dati anomali: MAE è più sensibile ai dati anomali rispetto alla Mean Squared Error (MSE). Ciò significa che l'algoritmo penalizza maggiormente i valori anomali o fuori dall'ordine, il che può essere utile quando ci sono dati che non seguiscono una distribuzione normale.
- Robustezza alle variazioni: MAE è più robusto rispetto alla MSE alle variazioni nelle dimensioni dei dati. Ciò significa che l'algoritmo può funzionare bene anche se i dati hanno dimensioni diverse.
- Interpretabilità: MAE è più facile da interpretare rispetto alla MSE. Ad esempio, un modello con un errore medio assoluto di 0,5 significa che il modello sbaglia mediamente di 0,5 unità.
Perché queste due scelte insieme?
La combinazione di SGD e MAE può essere particolarmente efficace in scenari in cui:- Ci sono dati con un grande spazio di valori possibili per le features e per le etichette.
- I dati contengono anormalità o valori anomali.
- La dimensione dei dati è grande o variabile.


 " il beta 3 mi da piccole/grandi
" il beta 3 mi da piccole/grandi soddisfazioni già al primo colpo
soddisfazioni già al primo colpo
 l'early lo preimposto dalla gui come anche il min.delta sono valori di addestramento
l'early lo preimposto dalla gui come anche il min.delta sono valori di addestramento



")











