Lottopython
Advanced Member >PLATINUM<
entro nel dettaglio e ti rispondo :
sono parametri che sto variando di test in test in verità sono alla Beta 21 e ho potuto verificare che i range bassi di impostazione hanno sempre piu successo nel breve periodo e come anche le ruote
Nella funzione carica_dati, viene creato un array X (input) che consente di raccogliere i dati delle estrazioni precedenti, e un array y (output) che corrisponde ai numeri dell'estrazione successiva.
Ecco come viene fatto:
Quindi, l'input consiste nelle estrazioni precedenti e l'output è l'estrazione successiva, come descritto nella tua domanda.
Sì, nella funzione crea_modello, ci sono specifiche riguardo alla configurazione del modello LSTM.
Inoltre:
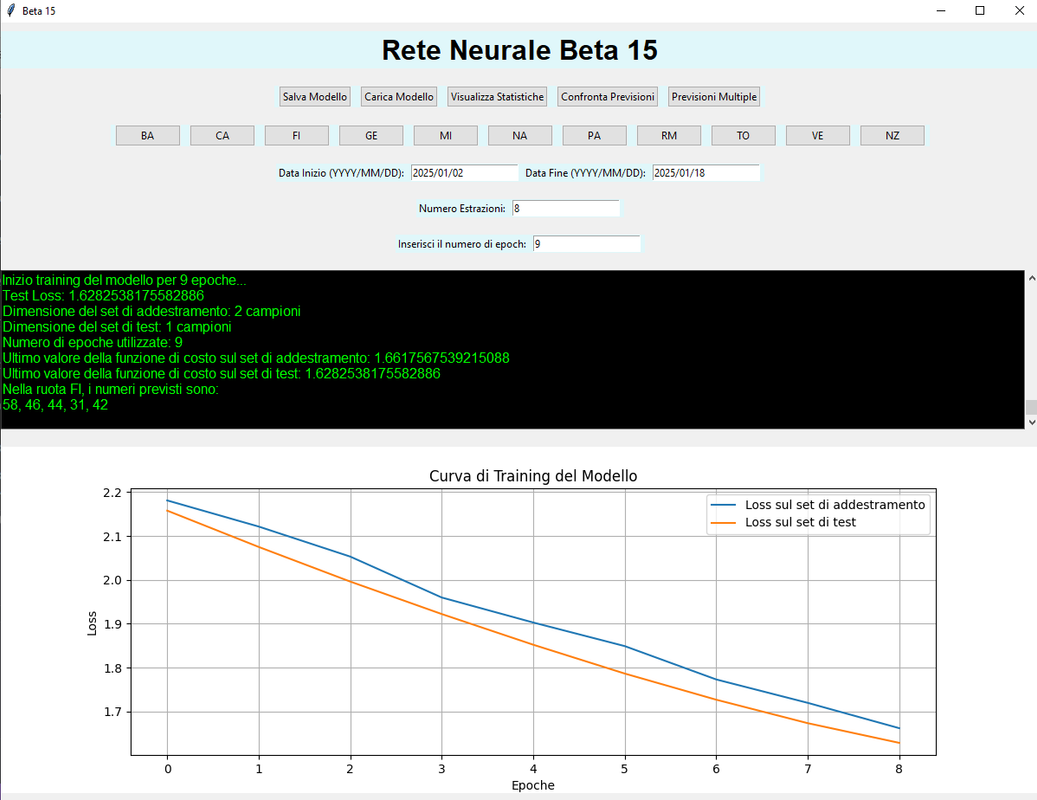
nell'insieme è abbastanza stabile per quanto riguarda le ambate e l'ambo a tutte ,le ruote piu gettonate sono Bari Napoli Palermo cosa che ho potuto verificare negli ultimi 6 mesi del 2024 .
a tempo perso ne vale la pena .
sono parametri che sto variando di test in test in verità sono alla Beta 21 e ho potuto verificare che i range bassi di impostazione hanno sempre piu successo nel breve periodo e come anche le ruote
1. L'addestramento si basa sempre sul prevedere i numeri in base all'estrazione precedente? Cioè input = estr. precedente e output = estr. successiva?
Sì, nel codice fornito, il modello LSTM è progettato per prevedere i numeri dell'estrazione successiva sulla base delle estrazioni precedenti.Nella funzione carica_dati, viene creato un array X (input) che consente di raccogliere i dati delle estrazioni precedenti, e un array y (output) che corrisponde ai numeri dell'estrazione successiva.
Ecco come viene fatto:
Codice:
X, y = [], []
for i in range(len(numeri_normalizzati) - num_estrazioni):
X.append(numeri_normalizzati[i:i + num_estrazioni]) # Estrazione precedente
y.append(numeri_normalizzati[i + num_estrazioni]) # Estrazione successivaQuindi, l'input consiste nelle estrazioni precedenti e l'output è l'estrazione successiva, come descritto nella tua domanda.
Sì, nella funzione crea_modello, ci sono specifiche riguardo alla configurazione del modello LSTM.
Dettagli della configurazione del modello:
- Numero di neuroni:
- Il primo layer LSTM ha 128 neuroni.
- Il secondo layer LSTM ha 64 neuroni.
- Dropout:
- È presente un layer Dropout dopo il primo layer LSTM, con un tasso di dropout del 30% (0.3).
- Un secondo layer Dropout con un tasso di dropout del 20% (0.2) segue il secondo layer LSTM.
- mano mano li modifico
Codice:
def crea_modello(X_train, y_train):
model = Sequential()
model.add(Input(shape=(X_train.shape[1], X_train.shape[2])))
model.add(LSTM(128, return_sequences=True, kernel_regularizer=tf.keras.regularizers.l2(0.01)))
model.add(Dropout(0.3))
model.add(LSTM(64, kernel_regularizer=tf.keras.regularizers.l2(0.01)))
model.add(Dropout(0.2))
model.add(Dense(y_train.shape[1]))
# Compilazione del modello
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.001), loss='mean_squared_error')
return modelInoltre:
- Loss Function: La funzione di perdita utilizzata è mean_squared_error, che è comune per i problemi di regressione.
- Ottimizzatore: Stai usando l'ottimizzatore Adam con un tasso di apprendimento di 0.001.
nell'insieme è abbastanza stabile per quanto riguarda le ambate e l'ambo a tutte ,le ruote piu gettonate sono Bari Napoli Palermo cosa che ho potuto verificare negli ultimi 6 mesi del 2024 .
a tempo perso ne vale la pena .
 . Se non fosse per te probabilmente mi sarei già arreso perché con questo linguaggio di programmazione faccio fatica
. Se non fosse per te probabilmente mi sarei già arreso perché con questo linguaggio di programmazione faccio fatica





 soddisfazioni già al primo colpo
soddisfazioni già al primo colpo