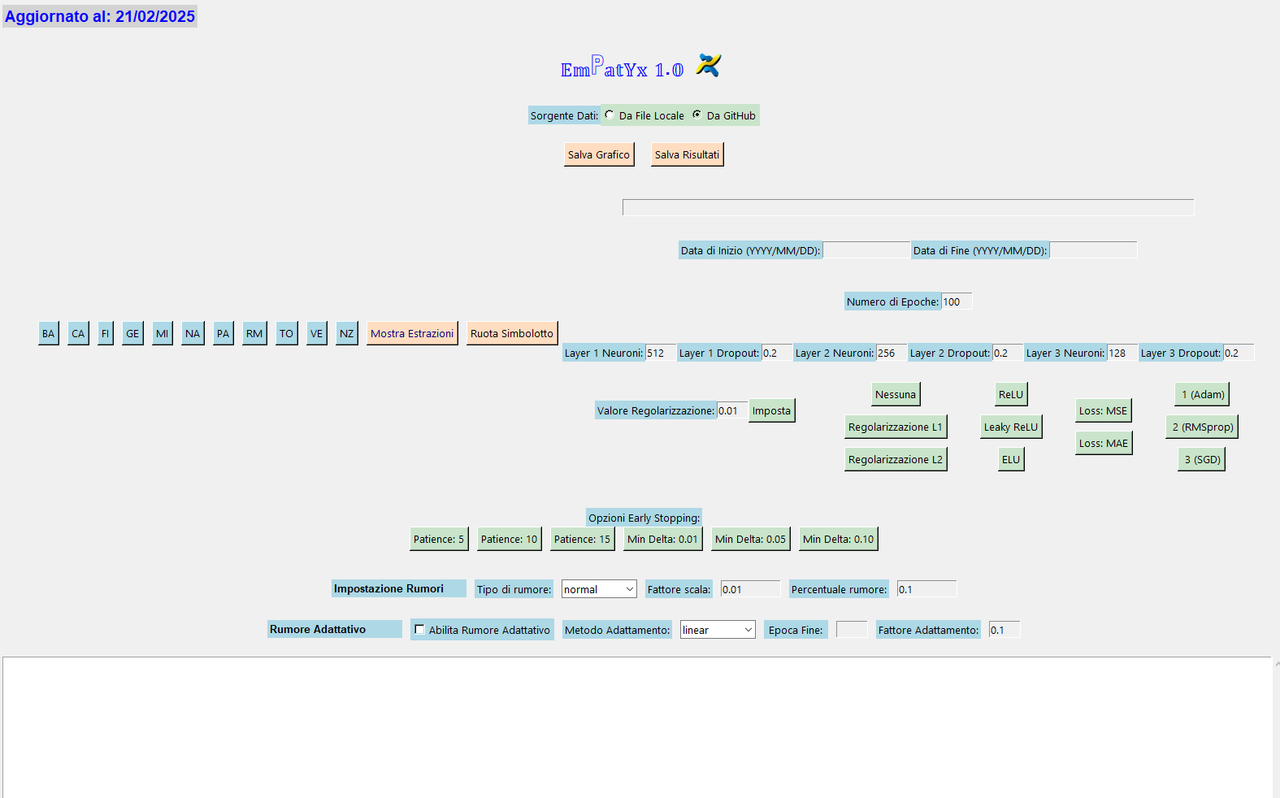
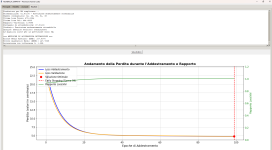
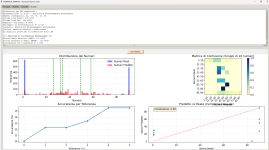
esempio di analisi su estrazione passata , poi segue una previsione ATTUALE.
ESEGUO train : Range di estrazioni usato per il training della rete : [6071-7083] 1013 estrazioni 2019/07/02 - 2025/06/07 Ruota di ROMA.
estraggo i primi 5 numeri da ordinamento SCORE
estraggo i primi 5 numeri da ordinamento %max train rete
completo con numeri presi da (studio sui sincroni) , prob. montecarlo , Markow Chain 2 stati ,
IMMETTO tutti i numeri nella finestra "Selezione numeri per previsione trend".
ELEABORO ...
--- Analisi Trend Numeri Selezionati ---
• Parametro N°_Max_TREND: 3
• Range estrazioni considerate: 1013
------------------------------------------------------------
Num | Max | Trend | Prob.Orig | Hazard Rate | R (curr/avg) | Prob.Log | Dur.res | Ritardo
--------------------------------------------------------------------------------------------------------------
8 | 2 | 3 | 56.0% | 28.6% | 1.31 | 26.9% | 0.4 | 7 x
10 | 2 | 1 | 48.0% | N/A | N/A | N/A | N/A | 2 x
36 | 3 | 1 | 50.0% | N/A | N/A | N/A | N/A | 21 x
39 | 3 | 1 | 50.0% | N/A | N/A | N/A | N/A | 21 x
40 | 4 | 3 | 60.0% | 9.1% | 1.39 | 26.9% | 0.1 | 2
44 | 5 | 1 | 54.0% | N/A | N/A | N/A | N/A | 0
47 | 3 | 1 | 50.0% | N/A | N/A | N/A | N/A | 1
54 | 4 | 1 | 52.0% | N/A | N/A | N/A | N/A | 11
55 | 3 | 1 | 50.0% | N/A | N/A | N/A | N/A | 19
63 | 3 | 3 | 58.0% | 11.1% | 1.32 | 26.9% | 0.2 | 12 x
70 | 4 | 1 | 52.0% | N/A | N/A | N/A | N/A | 0
71 | 3 | 1 | 50.0% | N/A | N/A | N/A | N/A | 0
72 | 3 | 3 | 58.0% | 36.4% | 1.33 | 26.9% | 0.5 | 1 x
77 | 3 | 1 | 50.0% | N/A | N/A | N/A | N/A | 78
83 | 3 | 1 | 50.0% | N/A | N/A | N/A | N/A | 0
87 | 4 | 1 | 52.0% | N/A | N/A | N/A | N/A | 44
Spiegazione metriche:
- Prob.Orig: Probabilità originale di continuazione del trend
- Hazard Rate: Probabilità empirica che il trend continui
- R (curr/avg): Rapporto tra trend attuale e media storica
- Prob.Log: Probabilità basata su modello logistico
- Dur.res: Durata residua attesa del trend
- Ritardo: Numero di estrazioni dall'ultima uscita (0=uscito nell'ultima estrazione, se non uscito nel range RIT=range)
================================================================================

REPORT ANALITICO COMPLETO - STRATEGIA DI GIOCO

Parametri:
• N°_Max_TREND = 3
• Range estrazioni considerate = 1013
================================================================================

TOP NUMERI DA CONSIDERARE
--------------------------------------------------------------------------------

Migliori per trend continuativo:
- N° 8: Trend=3, Prob=56%, H.Rate=29%, R=1.31
- N° 40: Trend=3, Prob=60%, H.Rate=9%, R=1.39
- N° 63: Trend=3, Prob=58%, H.Rate=11%, R=1.32

Migliori per probabilità di continuazione:
- N° 40: Prob=60%, Trend=3, H.Rate=9%, R=1.39
- N° 63: Prob=58%, Trend=3, H.Rate=11%, R=1.32
- N° 72: Prob=58%, Trend=3, H.Rate=36%, R=1.33

Migliori per statistica storica (Hazard Rate):
- N° 72: H.Rate=36%, Trend=3, Prob=58%, R=1.33
- N° 8: H.Rate=29%, Trend=3, Prob=56%, R=1.31
- N° 63: H.Rate=11%, Trend=3, Prob=58%, R=1.32
--------------------------------------------------------------------------------

TOP NUMERI PER PUNTEGGIO INTEGRATO:
- N° 72: Punteggio=44.25, Trend=3, H.Rate=36.4%, R=1.33
- N° 8: Punteggio=40.35, Trend=3, H.Rate=28.6%, R=1.31
- N° 63: Punteggio=31.62, Trend=3, H.Rate=11.1%, R=1.32
- N° 40: Punteggio=30.61, Trend=3, H.Rate=9.1%, R=1.39
--------------------------------------------------------------------------------

NUMERI APPENA USCITI (ritardo=0):
44, 70, 71, 83

STRATEGIA CONSIGLIATA:
8-10-38-39-40-63-72 ROMA
--------------------------------------------------------------------------------
STATISTICHE GLOBALI
------------------------------------------------------------
• Estrazioni analizzate: 1013
• Numeri con trend ≥3: 4
• Numeri con Hazard Rate >50%: 12
• Numeri con R >1.3 (trend lunghi): 4
• Numeri appena usciti (ritardo=0): 4
================================================================================
ED ECCO IL RISULTATO 8-10-38-39-40-63-72 : ESITO al 1° colpo di gioco ambo 72-36

Nessuna correlazione significativa trovata tra i numeri selezionati
ESEGUO NUOVA RICERCA 23\10\2025 RUOTA ROMA
-- Analisi Trend Numeri Selezionati ---
Range di estrazioni usato per il training della rete : [6071-7161] 1091 estrazioni 2019/07/02 - 2025/10/23
RUOTA ROMA
SCORE 32-15-13-48-79-55
rete %max 68-72-90-9-10
Studio Sincroni 13-14-55-84-44
monte carlo 14-68-15-44-74
markov chain 2 statu 79-82-54-6-14
ESEGUO PREVISIONE TREND
• Parametro N°_Max_TREND: 3
• Range estrazioni considerate: 1091
------------------------------------------------------------
Num | Max | Trend | Prob.Orig | Hazard Rate | R (curr/avg) | Prob.Log | Dur.res | Ritardo
--------------------------------------------------------------------------------------------------------------
6 | 3 | 1 | 50.0% | N/A | N/A | N/A | N/A | 41 X
9 | 3 | 1 | 50.0% | N/A | N/A | N/A | N/A | 25 X
10 | 2 | 1 | 48.0% | N/A | N/A | N/A | N/A | 1 X
13 | 5 | 5 | 70.0% | 0.0% | 2.19 | 4.7% | 0.0 | 1 X
14 | 4 | 3 | 60.0% | 18.8% | 1.32 | 26.9% | 0.2 | 1 X
15 | 3 | 1 | 50.0% | N/A | N/A | N/A | N/A | 11
32 | 4 | 1 | 52.0% | N/A | N/A | N/A | N/A | 0
44 | 5 | 1 | 54.0% | N/A | N/A | N/A | N/A | 11
48 | 4 | 1 | 52.0% | N/A | N/A | N/A | N/A | 0
54 | 4 | 1 | 52.0% | N/A | N/A | N/A | N/A | 31
55 | 4 | 1 | 52.0% | N/A | N/A | N/A | N/A | 0
68 | 4 | 1 | 52.0% | N/A | N/A | N/A | N/A | 11
72 | 3 | 1 | 50.0% | N/A | N/A | N/A | N/A | 22
74 | 3 | 1 | 50.0% | N/A | N/A | N/A | N/A | 11
79 | 4 | 1 | 52.0% | N/A | N/A | N/A | N/A | 3
82 | 3 | 1 | 50.0% | N/A | N/A | N/A | N/A | 5
84 | 2 | 3 | 56.0% | 30.0% | 1.27 | 26.9% | 0.3 | 3 X
90 | 4 | 1 | 52.0% | N/A | N/A | N/A | N/A | 8
Spiegazione metriche:
- Prob.Orig: Probabilità originale di continuazione del trend
- Hazard Rate: Probabilità empirica che il trend continui
- R (curr/avg): Rapporto tra trend attuale e media storica
- Prob.Log: Probabilità basata su modello logistico
- Dur.res: Durata residua attesa del trend
- Ritardo: Numero di estrazioni dall'ultima uscita (0=uscito nell'ultima estrazione, se non uscito nel range RIT=range)
================================================================================
REPORT ANALITICO COMPLETO - STRATEGIA DI GIOCO
Parametri:
• N°_Max_TREND = 3
• Range estrazioni considerate = 1091
================================================================================
TOP NUMERI DA CONSIDERARE
--------------------------------------------------------------------------------
Migliori per trend continuativo:
- N° 13: Trend=5, Prob=70%, H.Rate=0%, R=2.19
- N° 14: Trend=3, Prob=60%, H.Rate=19%, R=1.32
- N° 84: Trend=3, Prob=56%, H.Rate=30%, R=1.27
Migliori per probabilità di continuazione:
- N° 13: Prob=70%, Trend=5, H.Rate=0%, R=2.19
- N° 14: Prob=60%, Trend=3, H.Rate=19%, R=1.32
- N° 84: Prob=56%, Trend=3, H.Rate=30%, R=1.27
Migliori per statistica storica (Hazard Rate):
- N° 84: H.Rate=30%, Trend=3, Prob=56%, R=1.27
- N° 14: H.Rate=19%, Trend=3, Prob=60%, R=1.32
- N° 13: H.Rate=0%, Trend=5, Prob=70%, R=2.19
--------------------------------------------------------------------------------
TOP NUMERI PER PUNTEGGIO INTEGRATO:
- N° 84: Punteggio=41.07, Trend=3, H.Rate=30.0%, R=1.27
- N° 14: Punteggio=35.44, Trend=3, H.Rate=18.8%, R=1.32
-

N° 13: Punteggio=23.76, Trend=5, H.Rate=0.0%, R=2.19
--------------------------------------------------------------------------------
NUMERI APPENA USCITI (ritardo=0):
32, 48, 55
NUMERI A RISCHIO (trend lungo, possibile inversione):
13
STRATEGIA CONSIGLIATA:
--------------------------------------------------------------------------------
69-10-13-14-84 ROMA
STATISTICHE GLOBALI
------------------------------------------------------------
• Estrazioni analizzate: 1091
• Numeri con trend ≥3: 3
• Numeri con Hazard Rate >50%: 15
• Numeri con R >1.3 (trend lunghi): 2
• Numeri appena usciti (ritardo=0): 3
===============================================================================
SEMBRA NON SIA POSSIBILE COMMENTARE IL POST A DISTANZA DI 6 MESI , COMUNQUE OGGI 11/05/2026 MI CAPITA DI RIVEDERE IL POST A DISTANZA DI TEMPO E QUINDI COMMENTO LA PREVISIONE RICAVATA DAI PRIMI ALGORITMI SVILUPPATI IN PYTHON PREVISIONE ROMA 23/10/2025 10-13-14-69-81 TOT 5 NUM 3°COLPO 14-10 4°COLPO 10-13 CON MIO SOMMO PIACERE $$

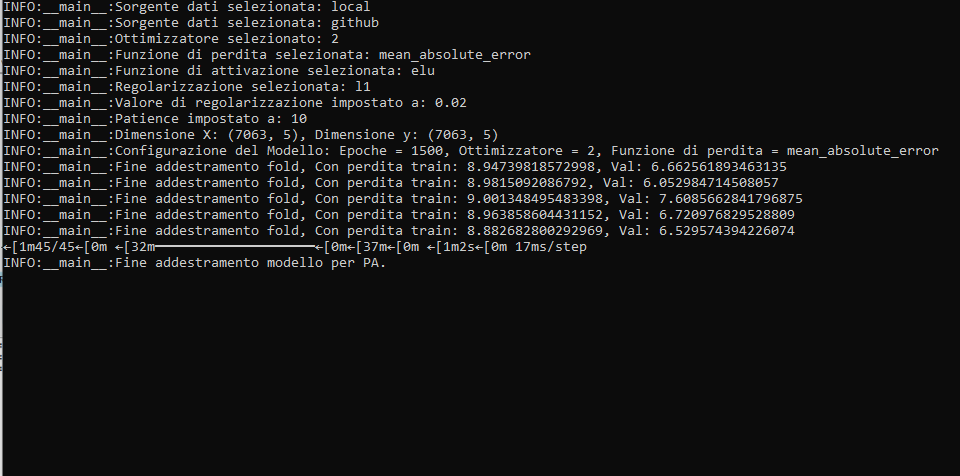

")