vinc01
Advanced Member
@mattia73 quello che hai scritto è statisticamente corretto, ho stimato quanto è grande l'errore, 10,86% ± 0,30% (intervallo 95%) ≈ 10,56% – 11,16% dunque hai ragione quando scrivi che siamo nel rumore di campionamento. Tuttavia, non contestando la matematica, posso solo aggiungere che: concordo sul fatto che la probabilità teorica P=1− (88 / 5) (90 / 5) sia corretta.Da analista: il codice è scritto bene, backtest incluso e onesto ma il motore non può funzionare per ragioni matematiche di base, indipendentemente da quanti dati storici si usino.
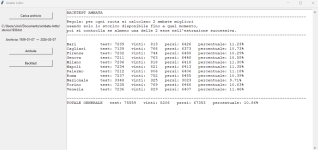
Il backtest su 25 anni di archivio (7/3/2001 – 7/3/2026) lo dimostra in modo definitivo.
La probabilità casuale di indovinare almeno 1 numero su 2 proposti in una estrazione da 5 su 90 è:
P = 1 - C(88,5) / C(90,5) = 10,86%
Il totale generale è 10,78% contro il 10,86% atteso dal caso puro. La differenza è di 8 centesimi di punto percentuale su 41.408 test , siamo letteralmente nel rumore di campionamento.
Ruota Test Vinti % Bari 3806 442 11,61% Cagliari 3806 412 10,83% Firenze 3806 407 10,69% Genova 3806 373 9,80% Milano 3806 422 11,09% Napoli 3806 410 10,77% Palermo 3806 457 12,01% Roma 3806 421 11,06% Nazionale 3348 325 9,71% Torino 3806 397 10,43% Venezia 3806 397 10,43% TOTALE 41408 4463 10,78%
Mattia73
Il punto interessante del mio esperimento non era confutarla, ma verificarla empiricamente con un metodo deterministico di selezione dei numeri basato su dati storici. Il backtest su oltre 41.400 simulazioni mostra una frequenza di successo del 10,78%, quindi sostanzialmente coincidente con il valore teorico di 10,86%. Questo suggerisce che il metodo non introduce alcuna informazione predittiva rispetto al caso, e conferma l’ipotesi di indipendenza delle estrazioni. Saluti e stamani sul lavoro non potevo fare molto per una risposta migliore.

")

")








